
はじめに
前回の記事では、次世代AIライブラリ Detectron2 の推論方法について説明しました。

今回は、カスタムデータで学習させていきます。
前提条件
前提条件は、以下の通りです。
- OS は Linux または、WSL2
- Python >= 3.7 ※3.8.10を使用します。
- PyTorch == 1.11.0+cu113 ※ バージョンを合わせる必要があります。
- OpenCV >= 4.5 ※4.5.5を使用します。
- CUDA-Toolkit == 11.3.1
- Detectron2 == 0.6
CUDA と PyTorch と Detectron2 のバージョンは合わせる必要があるので、前回を参考にしてください。
学習に使用するデータについて
学習に使用するデータは、Yolov5 や、Yolact-Edge で使用したデータを使用します。
入手方法はこちらの記事を参考にしてください。
以下の画像のようにアノテーションしたデータです。
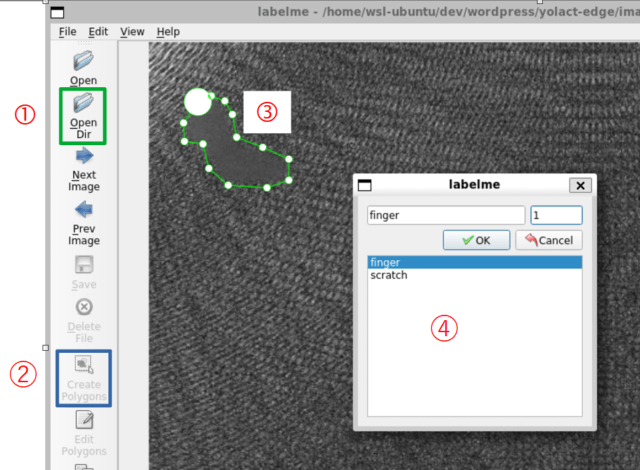
Class1_def の 1.png ~ 15.png, Class2_def の 16.png ~ 30.png を、使用していきます。
データ形式は COCO が最も簡単に学習させることができます。
COCO 形式のデータセットの作成方法はこちらの記事を参考にしてください。
images_annotation-coco フォルダをまるごとコピーして使用します。
データの準備
環境を合わせるために、フォルダとデータの配置を合わせていきます。
cd ~/detectron2-dev
mkdir detectron2-train
cd detectron2-train
touch detectron_train_COCO.py
code .今作成した detectron2-train フォルダに images_anotation-coco もコピーしてきてください。
学習用コードの作成
detectron_train_COCO.py を以下のように作成してください。
コードは、こちらを参考にしています。
import os
import cv2
import random
from detectron2 import model_zoo
from detectron2.engine import DefaultTrainer
from detectron2.config import get_cfg
from detectron2.utils.visualizer import Visualizer
from detectron2.data import DatasetCatalog, MetadataCatalog
from detectron2.data.datasets import register_coco_instances
register_coco_instances("train", {}, "./images_annotation-coco/annotations.json", "./images_annotation-coco")
metadata = MetadataCatalog.get("train")
dataset_dicts = DatasetCatalog.get("train")
for d in random.sample(dataset_dicts, 1):
img = cv2.imread(d["file_name"])
visualizer = Visualizer(img[:, :, ::-1], metadata=metadata, scale=1.0)
vis = visualizer.draw_dataset_dict(d)
cv2.imshow("frame", vis.get_image()[:, :, ::-1])
cv2.waitKey(0)
cv2.destroyAllWindows()
cfg = get_cfg()
cfg.OUTPUT_DIR = './output'
cfg.CUDA = 'cuda:0'
cfg.merge_from_file(model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"))
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml")
cfg.DATASETS.TRAIN = ('train',)
cfg.DATASETS.TEST = () # no metrics implemented for this dataset
cfg.DATALOADER.NUM_WORKERS = 2
cfg.SOLVER.IMS_PER_BATCH = 2
cfg.SOLVER.BASE_LR = 0.00025
cfg.SOLVER.MAX_ITER = 500
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 128 # faster, and good enough for this toy dataset
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 3
os.makedirs(cfg.OUTPUT_DIR, exist_ok=True)
trainer = DefaultTrainer(cfg)
trainer.resume_or_load(resume=False)
trainer.train()コードの説明をしていきます。
register_coco_instances("train", {}, "./images_annotation-coco/annotations.json", "./images_annotation-coco")register_coco_instances は、COCO形式の データセットを Detectron2 のデータ形式に登録することができます。たった1行でデータローダーへの変換もしてくれます。簡単すぎます。
引数は、(name, metadata, json_file, image_root) となります。
今回でいうと、
- name=”train” 訓練用なので “train” としておきます。
- metadata={} 空の辞書にしておき、あとで登録します。
- json_file=”./images_annotation-coco/annotations.json”
- image_root=”./images_annotation-coco” JPEGImages までのフォルダパスを指定します。
metadata = MetadataCatalog.get("train")
dataset_dicts = DatasetCatalog.get("train")MetadataCatalog.get(“train”) は、先ほど登録した “train” のデータから、metadata を作成します。この metadata は、評価や可視化において非常に便利になります。
DatasetCatalog.get(“train”) は、ラベルを取得します。 0=__background__, 1=finger のように、推論結果とクラスラベルを紐づける辞書となります。
for d in random.sample(dataset_dicts, 1):
img = cv2.imread(d["file_name"])
visualizer = Visualizer(img[:, :, ::-1], metadata=metadata, scale=1.0)
vis = visualizer.draw_dataset_dict(d)
cv2.imshow("frame", vis.get_image()[:, :, ::-1])
cv2.waitKey(0)
cv2.destroyAllWindows()学習に使用する画像をランダムで1枚取得し、表示するプログラムです。
Visualizer(img[:, :, ::-1], metadata=metadata, scale=1.0) は、Detectron2 の Visualizer クラスを使用します。metadata は、先ほど作成した metadata を使用します。
あとは、draw_dataset_dict を使用するだけでアノテーション情報を画像に描画してくれます。
あとは、cv2.imshow() で表示するだけです。
cfg = get_cfg()
cfg.OUTPUT_DIR = './output'
cfg.CUDA = 'cuda:0'get_cfg() は、学習や推論の設定をこのクラスですべて管理できます。
cfg.OUTPUT_DIR = ‘./output’ は、結果の出力フォルダを指定します。
cfg.CUDA = ‘cuda:0’ は、使用するデバイス (CPUとかGPUとか)を指定できます。
非常に簡単に分かりやすく設定が変更できます。
cfg.merge_from_file(model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"))
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml")cfg.merge_from_file は、使用するインスタンスセグメンテーションの設定ファイルを読み込みます。
cfg.MODEL.WEIGHTS は、設定ファイルからネットワークの重みを読み込みます。
cfg.DATASETS.TRAIN = ('train',)
cfg.DATASETS.TEST = () # no metrics implemented for this dataset
cfg.DATALOADER.NUM_WORKERS = 2cfg.DATASETS.TRAIN = (‘train’,) は “train” データセットを学習に使用するために cfg へ読み込ませます。cfg.DATASETS.TEST は検証用のデータセットを指定します。
cfg.DATALOADER.NUM_WORKERS は、データローダーの数を指定します。
cfg.SOLVER.IMS_PER_BATCH = 2
cfg.SOLVER.BASE_LR = 0.00025
cfg.SOLVER.MAX_ITER = 500cfg.SOLVER は、学習率やイテレーションの数を指定します。ひとまず、デフォルトを指定しておきます。loss が発散するようであれば、変更してください。
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 128 # faster, and good enough for this toy dataset
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 3cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE は デフォルトの128で大丈夫です。
cfg.MODEL.ROI_HEADS.NUM_CLASSES は、__background__を含めるので、3クラスになります。
os.makedirs(cfg.OUTPUT_DIR, exist_ok=True)
trainer = DefaultTrainer(cfg)
trainer.resume_or_load(resume=False)
trainer.train()./output フォルダを作成し、DefaultTrainer に先ほど作成した cfg を渡します。
resume_or_load() は、resume=True でOUTPUT_DIR の last_checkpoint から学習を始めます。
trainer.train() で学習開始です。
学習の実行と結果の確認
早速、学習を実行します。
python3 detectron_train_COCO.pyこちらを実行すると、私の環境で約20分で学習が完了します。早いです。
出力は以下のようになります。
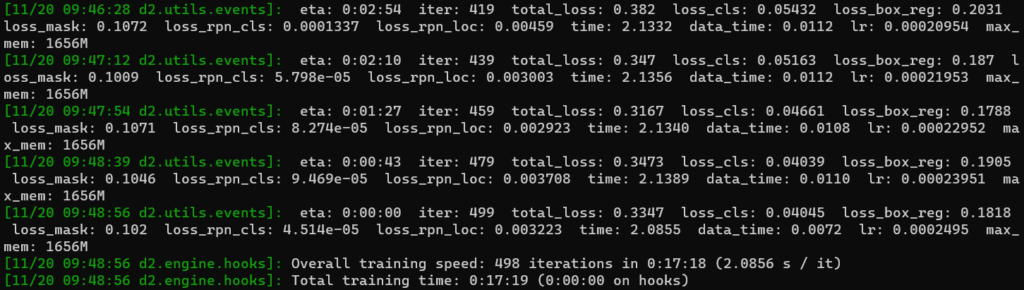
結果の見方は Yolact-Edge や、Yolov5 と同じです。loss に注意しておきましょう。
学習が完了すると、./output フォルダに
- last_checkpoint 最後のモデル保存データ、resume=Trueで続けて学習に使用できる。
- metrics.json 学習結果の確認に使用できます。
- model_final.pth 推論に使用する weight ファイル
が作成されています。
model_final.pth を用いて推論すると以下のような出力が得られます。

カスタムデータでの推論方法については、次回の記事で説明します。
おわりに
今回は Detectron2 をカスタムデータで学習させる方法について説明しました。
色々な設定項目の説明をしましたが、数値に関してはほとんどデフォルトでも動きます。
次回はカスタムデータの推論方法について説明します。
その後は、インスタンスセグメンテーション以外の学習方法についても説明していきます。

コメント