はじめに
今まではROS2の説明をしていましたが、自分で見返すようにAIの記事も作成していきます。
今回は物体認識に広く使われている Yolov5 の学習方法について説明します。
Yolov5の公式githubはこちらです。
アノテーションの方法から学習時に使用するオプションの説明もします。
前提条件
前提条件は、以下の通りです。
- pytorch >= 1.8.0 がインストールされている(今回は1.12.1+cu116です)
- opencv-python がインストールされている(今回は4.5.5で、numpy==1.23.3)
- git がインストールされている
- Ubuntu20.04 LTS (Windowsの場合は、pip3→pip, python3→pythonと置き換えてください)
- 今回はNVIDIA GeForce RTX 3050 Ti Laptop GPU (4GB) を使用します。CPUでも可。
opencv-python は “pip3 install opencv-python” でインストール可能です。
pytorch のインストールは公式サイトを参考にインストールしてください。
他にも必要なライブラリがありますが、No module named “XXX” と出てきたらその都度、pip3 install XXX でインストールしてください。
2023/10/17 追記
現在は下記のパッケージで動作します。
absl-py==2.0.0
cachetools==5.3.1
certifi==2023.7.22
charset-normalizer==3.3.0
colorama==0.4.6
contourpy==1.1.1
cycler==0.12.1
fonttools==4.43.1
gitdb==4.0.10
GitPython==3.1.37
google-auth==2.23.3
google-auth-oauthlib==1.0.0
grpcio==1.59.0
idna==3.4
kiwisolver==1.4.5
Markdown==3.5
MarkupSafe==2.1.3
matplotlib==3.8.0
numpy==1.23.3
oauthlib==3.2.2
opencv-python==4.8.1.78
packaging==23.2
pandas==2.1.1
Pillow==9.5.0
protobuf==4.24.4
psutil==5.9.6
py-cpuinfo==9.0.0
pyasn1==0.5.0
pyasn1-modules==0.3.0
pycocotools==2.0.7
pyparsing==3.1.1
python-dateutil==2.8.2
pytz==2023.3.post1
PyYAML==6.0.1
requests==2.31.0
requests-oauthlib==1.3.1
rsa==4.9
scipy==1.11.3
seaborn==0.13.0
six==1.16.0
smmap==5.0.1
tensorboard==2.14.1
tensorboard-data-server==0.7.1
thop==0.1.1.post2209072238
torch==1.11.0+cu113
torchaudio==0.11.0+cu113
torchvision==0.12.0+cu113
tqdm==4.66.1
typing_extensions==4.8.0
tzdata==2023.3
ultralytics==8.0.199
urllib3==2.0.6
Werkzeug==3.0.0アノテーションの準備
まずは以下のコマンドを実行してください。
cd ~
mkdir test-yolov5
cd test-yolov5
git clone -b v1.8.6 https://github.com/heartexlabs/labelImg.git
pip3 install pyqt5 lxml
pyrcc5 -o libs/resources.py resources.qrc
cd labelImg
python3 labelImg,py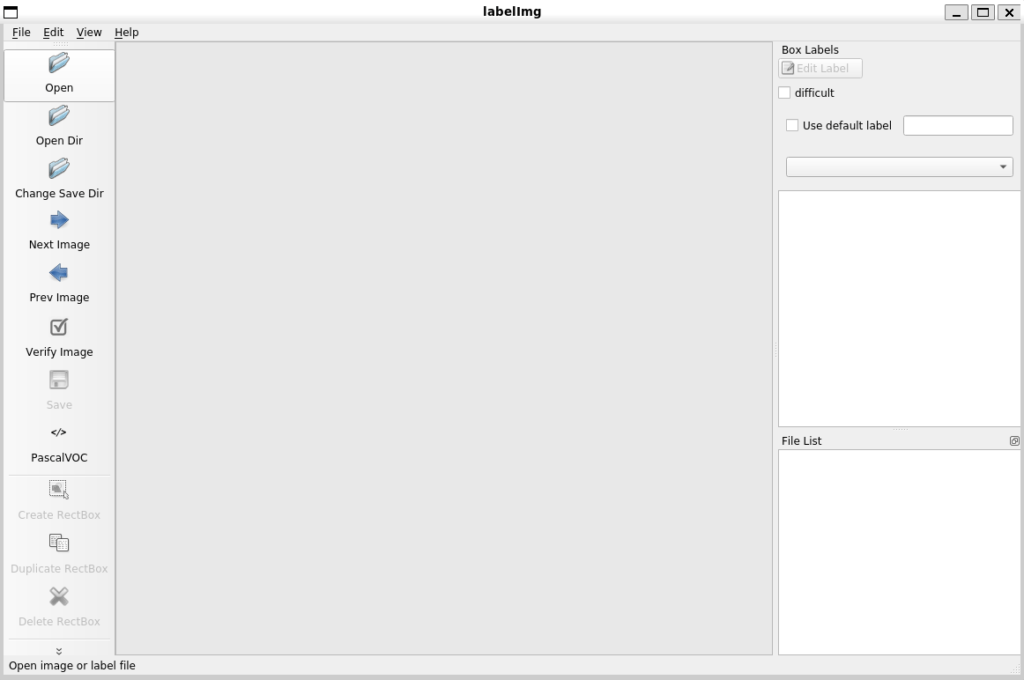
このような画面が立ち上がれば完了です。右上の x から一度閉じてください。
データの準備
今回は工業用品の不良検査にも使用できるようなデータセットを使用します。
こちらの公式サイトに詳しい説明があります。
wget の部分は URLバーに直接https://conferences.mpi-inf.mpg.de/dagm/2007/Class1.zipを打ち込んでも大丈夫です。どちらでも時間かかります。
cd ~/test-yolov5
mkdir images
cd images
wget https://conferences.mpi-inf.mpg.de/dagm/2007/Class1_def.zip
unzip Class1_def.zip
rm Class1_def.zip
wget https://conferences.mpi-inf.mpg.de/dagm/2007/Class2_def.zip
unzip Class2_def.zip
rm Class2_def.zip
mkdir images_annotationClass1_def, Class2_def から適当に15枚程度選択して、それぞれ images_annotation にコピーしてください。
今回は ファイル名が上書きされないように、Class1_def の 1.png ~ 15.png, Class2_def の 16.png ~ 30.png を images_annnotation にコピーしました。
アノテーション
画像が準備できたら、まずは検知したいクラスを用意します。
cd test-yolov5/labelImglabelImg の dataフォルダにある predefined_classes.txt を以下のように変更してください。
scratch
fingerscratch はひっかき傷、finger は指紋(にじみ?)のクラスとします。
ここまできたら、labelImg.py を起動します。
python3 labelImg.py起動したら下図のように、Opendir > images_annotation フォルダ を選択します。
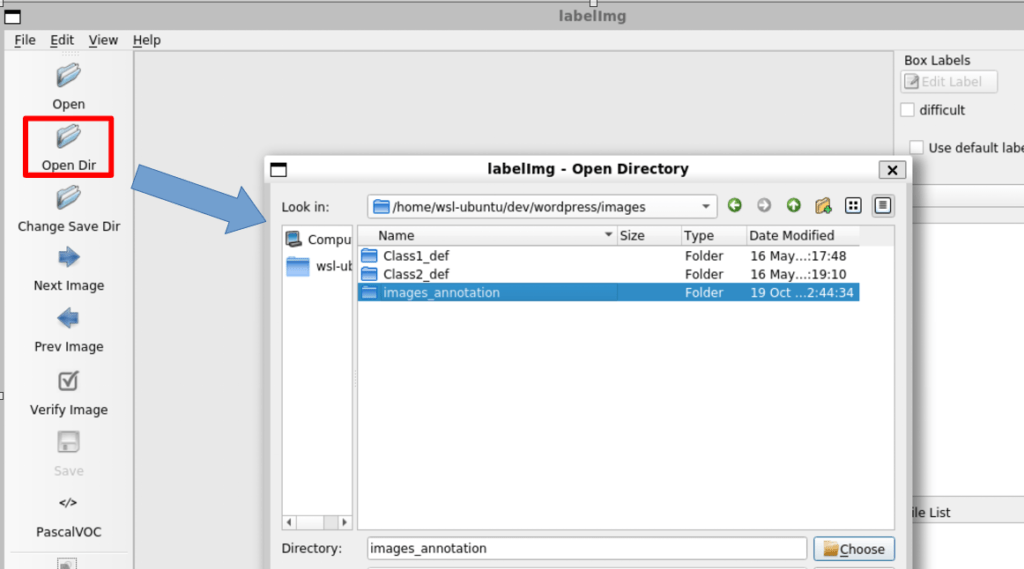
選択されたフォルダに画像があると、labelImg の画面に表示されます。
画面の簡単な説明は以下の通りです。

Yolov5 は対象クラスが映っている矩形とその中身を学習していくので、アノテーションは矩形を作成し、その矩形内に映るクラスを指定します。
labelImg 画面の Create RectBox をクリックするかキーボードの “w” を押すと、矩形の選択画面になります。
適当な部分でクリックし、ドラッグすると任意のサイズの矩形が作成できます。
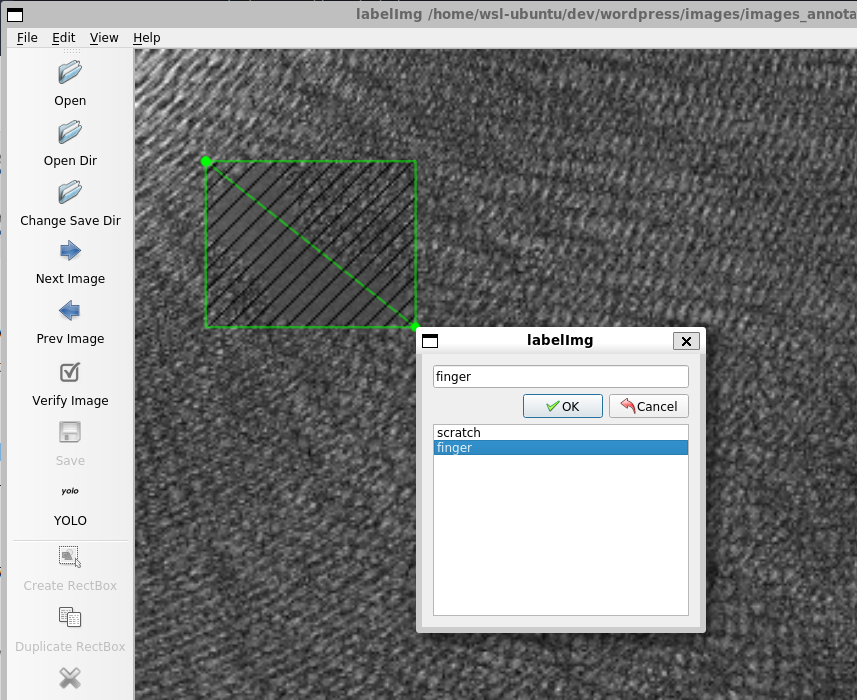
finger を選択し、OK を押します。あとは Save ボタンから保存してください。
保存するときに、.xml.txt ではなく .txt で保存されていることを確認してください。
.txt でないと、Prev Image で戻った時にアノテーション情報を確認することができません。
Next Image をクリックすると、次の画像へ行きますので、これを30枚分作成してください。
作成しましたら、images_annotation フォルダにある 1.txt を開いてください。
1 0.136719 0.159180 0.164062 0.134766中身はこのようになっています。
- 1 — クラスラベル。predefined_classes.txt と照合するとクラス名が分かります。
- 0.136719 — 矩形の中心の X 座標。画像の横幅を1として 0 ~ 1 で表されます。
- 0.159180 — 矩形の中心の Y 座標。画像の縦幅を1として 0 ~ 1 で表されます。
- 0.164062 — 矩形の横幅。画像の横幅を1として 0 ~ 1 で表されます。
- 0.134766 — 矩形の縦幅。画像の縦幅を1として 0 ~ 1 で表されます。
これだけです。数字を直接打ち込んで作成することも可能です。
その場合は、必ず小数点以下6桁で打ち込んでください。
yolov5の準備
Yolov5の準備をしていきます。
cd ~/test-yolov5
git clone -b v6.2 https://github.com/ultralytics/yolov5.git
cd yolov5適当なエディタでyolov5フォルダの requirements.txt を開き、以下に書き換えてください。
# YOLOv5 requirements
# Usage: pip install -r requirements.txt
# Base ----------------------------------------
matplotlib>=3.2.2
numpy>=1.18.5
#opencv-python>=4.1.1
Pillow>=7.1.2
PyYAML>=5.3.1
requests>=2.23.0
scipy>=1.4.1
#torch>=1.7.0
#torchvision>=0.8.1
tqdm>=4.64.0
protobuf<=3.20.1 # https://github.com/ultralytics/yolov5/issues/8012
# Logging -------------------------------------
tensorboard>=2.4.1
# wandb
# clearml
# Plotting ------------------------------------
pandas>=1.1.4
seaborn>=0.11.0
# Export --------------------------------------
# coremltools>=5.2 # CoreML export
# onnx>=1.9.0 # ONNX export
# onnx-simplifier>=0.4.1 # ONNX simplifier
# nvidia-pyindex # TensorRT export
# nvidia-tensorrt # TensorRT export
# scikit-learn==0.19.2 # CoreML quantization
# tensorflow>=2.4.1 # TFLite export (or tensorflow-cpu, tensorflow-aarch64)
# tensorflowjs>=3.9.0 # TF.js export
# openvino-dev # OpenVINO export
# Extras --------------------------------------
ipython # interactive notebook
psutil # system utilization
thop>=0.1.1 # FLOPs computation
# albumentations>=1.0.3
pycocotools>=2.0 # COCO mAP
# roboflow書き換えたら、以下を実行します。
pip3 install -r requirements.txt次は、学習用画像を読み込めるようにしていきます。
cd data
mkdir train valid
cd train
mkdir images labels
cd ../valid
mkdir images labels
cd ..
touch data.yamlフォルダの振り分けは、以下のようにしてください。
- train/images — 訓練に使用する画像データを入れる
- train/labels — 訓練に使用するラベルデータを入れる
- valid/images — 検証に使用する画像データを入れる
- valid/labels — 検証に使用するラベルデータを入れる
今回、訓練画像と検証画像は同じにするので、images_annotation からそれぞれコピーしてください。
今作成した data.yaml を開き、以下のコードを入力してください。
names:
- scratch
- finger
nc: 2
train: data/train/images
val: data/valid/imagesここまでできたら、いよいよ学習へ移ります。
Yolov5の学習
まずは、git clone した yolov5 のフォルダに移動します。
cd ~/test-yolov5/yolov5yolov5 の学習コマンドは以下のようになります。
python3 train.py --data data.yaml --cfg yolov5s.yaml --weights yolov5s.pt --batch-size 16 --epoch 30実行にしばらく時間がかかるので、待ちます。
RuntimeError: CUDA error: out of memoryと、表示される場合は、–batch-size 8 に変更してみてください。私は 8 に変更しました。
30epoch 終わると、最後に結果が表示されます。

“P” は検出率、”R” は検出したクラスが正しかった確率です。
次は、100epoch 実行し、結果を見てみます。
python3 train.py --data data.yaml --cfg yolov5s.yaml --weights yolov5s.pt --batch-size 8 --epoch 100結果は以下のようになります。

検出率である “P” がかなり上昇しました。mAP は数値が1に近づくほど、優秀なAIモデルということになります。
学習時の画像サイズの変更
次は、引数を追加してみます。
python3 train.py --data data.yaml --cfg yolov5s.yaml --weights yolov5s.pt --batch-size 8 --epoch 100 --imgsz 480Yolov5のデフォルトでは画像サイズを640として学習します。
画像サイズが横640x縦480の場合、画像の上下に 80px ずつ黒塗り部分を追加します。
–imgsz 480 を追加すると、縦480x横360にリサイズされ、画像の上下に 60px ずつ黒塗り部分を追加します。

結果は少し悪くなりました。画像が小さくなったので、Yolov5が不良を見つけづらいのだと思います。
次は画像を大きくしてやってみます。
python3 train.py --data data.yaml --cfg yolov5s.yaml --weights yolov5s.pt --batch-size 4 --epoch 100 --imgsz 960画像サイズを960にして学習させてみます。–batch-size を4に変更してあります。

“P” は上昇しましたが “R” が悪くなりました。
学習の際は、元の画像に近いサイズで学習させるほうが良さそうです。
学習時のメモリエラー対策 (–batch-size 以外)
python3 train.py --data data.yaml --cfg yolov5s.yaml --weights yolov5s.pt --batch-size 16 --epoch 100 --workers 0次は –workers 0 を追加して、–batch-size 16 で学習します。若干、学習が遅くなります
なぜか、”RuntimeError: CUDA error: out of memory” のようなメモリエラーは出ません。
Yolov5では、(というかPyTorchでは) 学習をスムーズに行うために事前に次のミニバッチをGPUに配置するようになっています。その準備数を –workers で指定します。
バッチサイズを小さくしたのにメモリエラーが出る場合は、–workers の値を小さくしてください。
AIモデルの変更
AIモデルの変更は、以下のように引数を変更します。
- –cfg yolov5n.yaml –weights yolov5n.pt … 最軽量、ラズパイでも2s程度で動作
- –cfg yolov5s.yaml –weights yolov5s.pt … 複雑でなければ大体これで見れます
- –cfg yolov5m.yaml –weights yolov5m.pt
- –cfg yolov5l.yaml –weights yolov5l.pt
- –cfg yolov5x.yaml –weights yolov5x.pt … 最重量、精度が高い
n < s < m < l < x の順に
学習のまとめ
まとめとして、以下のコマンドで学習してください。
python3 train.py --data data.yaml --cfg yolov5s.yaml --weights yolov5s.pt --batch-size 8 --epoch 200 --workers 2
良い結果が出ました。
実行結果は runs/train/exp に保存されています。
weight フォルダに、best.pt と last.pt があります。best.pt を使用していきます。
学習結果を用いて推論
今回は簡単に推論の方法を説明します。
cd ~/test-yolov5/yolov5
cp runs/train/exp/weights/best.pt best.pt
python3 detect.py --weight best.pt --source ~/test-yolov5/Class1_def結果は runs/detect/exp に保存されます。

他の画像はぜひ、ご自分の目で確認してみてください。
おわりに
Yolov5 の学習 ~ 推論の方法を説明しました。
学習方法はアノテーションの形式、使用するソフトさえわかれば非常にシンプルで分かりやすいと思います。それだけ、Yolov5 が分かりやすくできています。
次回は、Yolov5 の推論についてもう少し追加の説明と、簡単に追加学習する方法について説明できたらと思います。



コメント