はじめに
前回の記事では、Yolact-Edge をカスタムデータで学習させる方法について説明しました。

今回は、学習させたモデルを使用して、推論をする方法及び、コードの解説をしていきます。
最終的には、OpenCVで読み込んだ画像を簡単に推論できるように変更していきます。
前提条件
前提条件は、以下の通りです。
PyTorch は、1.9.x, 1.11.x で動くことを確認しています。
VSCode がないと、今回は非常に不便になります。必ずインストールしてください。
カスタムモデルの推論
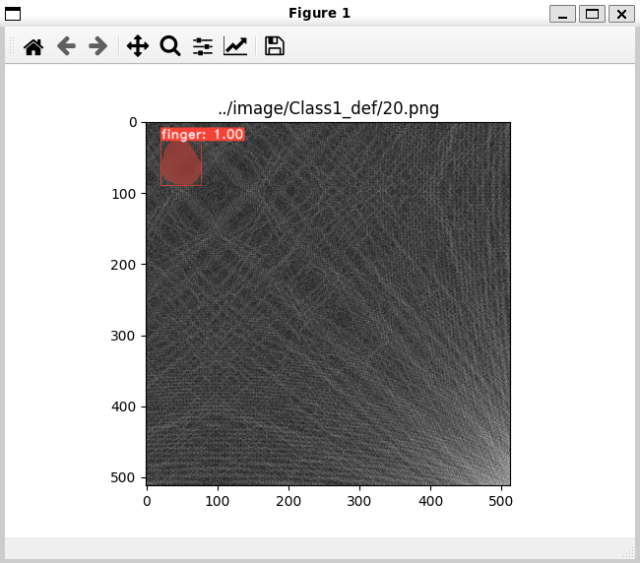
はじめに、前回の記事でも実施しましたが、元のプログラムを使用して推論を実行します。
cd ~/yolact-train/yolact_edge
python3 eval.py --trained_model=weights/my_mobilenetv2_config_4285_30000.pth --score_threshold=0.45 --top_k=3 --image=../image/Class1_def/2.png --config=my_mobilenetv2_config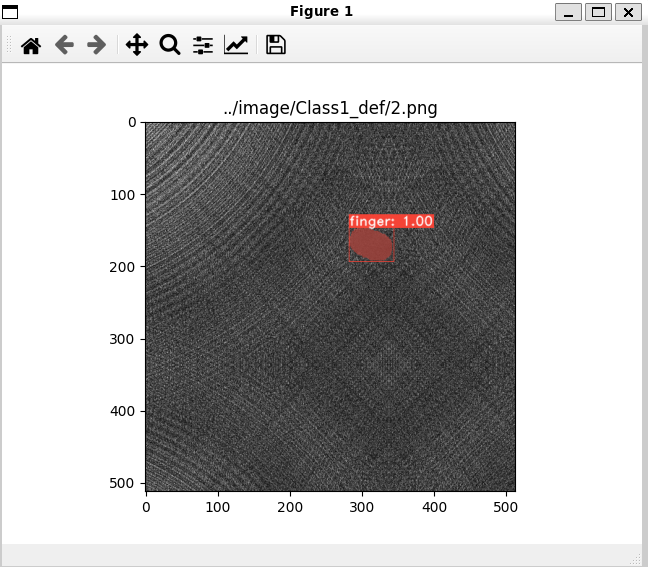
このように表示されていれば問題ありません。
推論プログラム作成の準備
次に、推論用のフォルダを作成し、githubからソースをダウンロードします。
mkdir ~/yolact-train/yolact-predict
cd yolact-predict
git clone https://github.com/haotian-liu/yolact_edge.git
cd yolact_edge
mkdir weights
code .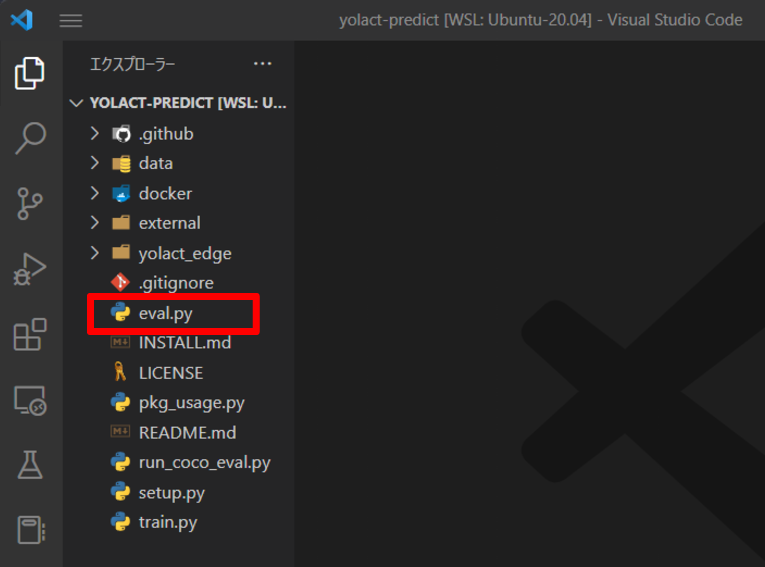
赤枠内の eval.py が推論用のプログラムとなります。コピーして使用します。
cp eval.py test_eval.pyさらに、前回の記事で作成した config.py と coco.py を上書きしておきます。
もしくは、前回の記事を参考に config.py と coco.py を変更してください。
メイン関数の変更
test_eval.py を変更していきます。元のプログラムは以下のようになります。
if __name__ == '__main__':
parse_args()
if args.config is not None:
set_cfg(args.config)
if args.trained_model == 'interrupt':
args.trained_model = SavePath.get_interrupt('weights/')
elif args.trained_model == 'latest':
args.trained_model = SavePath.get_latest('weights/', cfg.name)
if args.config is None:
model_path = SavePath.from_str(args.trained_model)
# TODO: Bad practice? Probably want to do a name lookup instead.
args.config = model_path.model_name + '_config'
print('Config not specified. Parsed %s from the file name.\n' % args.config)
set_cfg(args.config)
if args.detect:
cfg.eval_mask_branch = False
if args.dataset is not None:
set_dataset(args.dataset)
from yolact_edge.utils.logging_helper import setup_logger
setup_logger(logging_level=logging.INFO)
logger = logging.getLogger("yolact.eval")
with torch.no_grad():
if not os.path.exists('results'):
os.makedirs('results')
if args.cuda:
cudnn.benchmark = True
cudnn.fastest = True
if args.deterministic:
cudnn.deterministic = True
cudnn.benchmark = False
torch.set_default_tensor_type('torch.cuda.FloatTensor')
else:
torch.set_default_tensor_type('torch.FloatTensor')
if args.resume and not args.display:
with open(args.ap_data_file, 'rb') as f:
ap_data = pickle.load(f)
calc_map(ap_data)
exit()
if args.image is None and args.video is None and args.images is None:
if cfg.dataset.name == 'YouTube VIS':
dataset = YoutubeVIS(image_path=cfg.dataset.valid_images,
info_file=cfg.dataset.valid_info,
configs=cfg.dataset,
transform=BaseTransformVideo(MEANS), has_gt=cfg.dataset.has_gt)
else:
dataset = COCODetection(cfg.dataset.valid_images, cfg.dataset.valid_info,
transform=BaseTransform(), has_gt=cfg.dataset.has_gt)
prep_coco_cats()
else:
dataset = None
logger.info('Loading model...')
net = Yolact(training=False)
if args.trained_model is not None:
net.load_weights(args.trained_model, args=args)
else:
logger.warning("No weights loaded!")
net.eval()
logger.info('Model loaded.')
convert_to_tensorrt(net, cfg, args, transform=BaseTransform())
if args.cuda:
net = net.cuda()
evaluate(net, dataset)
これを、以下のように変更してください。
if __name__ == '__main__':
parse_args()
config = "my_mobilenetv2_config"
set_cfg(config)
cfg.eval_mask_branch = True
cfg.mask_proto_debug = False
use_cuda = True
if use_cuda:
cudnn.benchmark = True
cudnn.fastest = True
torch.set_default_tensor_type('torch.cuda.FloatTensor')
with torch.no_grad():
net = Yolact(training=False)
trained_model = "weights/my_mobilenetv2_config_4285_30000.pth"
net.load_weights(trained_model, args=args)
net.eval()
if use_cuda:
net = net.cuda()
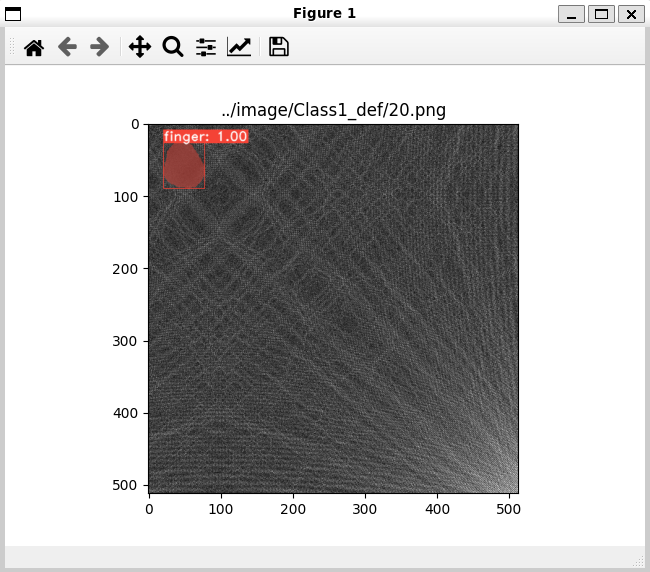
image_path = "../image/Class1_def/20.png"
evalimage(net, image_path)こちらを実行すると、以下のように画像が表示されるはずです。
trained_model と image_path は環境に合わせて変更してください。
OpenCVで読み込んだ画像を推論する
今までは、引数やファイル名を指定して推論をしていました。
次は OpenCV で読み込んだ画像を推論するプログラムを書いていきます。
test_eval.py プログラムの最終行
evalimage(net, image_path)の evalimage にカーソルを合わせて Ctrl + クリックします。すると、evalimage 関数に移動します。
def evalimage(net:Yolact, path:str, save_path:str=None, detections:Detections=None, image_id=None):
frame = torch.from_numpy(cv2.imread(path)).cuda().float()
batch = FastBaseTransform()(frame.unsqueeze(0))こちらが evalimage の冒頭部分です。
frame = torch.from_numpy(cv2.imread(path)).cuda().float()
で、画像を読み込んで PyTorch のテンソルを GPU に配置し、float 型に変換しています。
この中の cv2.imread(path) を メイン関数の方で実行するだけで大丈夫です。
test_eval.py の最終行の
image_path = "../image/Class1_def/20.png"
evalimage(net, image_path)を
from glob import glob
image_folder = "../image/Class1_def/"
image_list = glob(image_folder + "*.png")
for image_path in image_list:
frame = cv2.imread(image_path)
evalimage(net, frame)に変更します。
更に、evalimage 関数を変更していきます。
def evalimage(net:Yolact, path:str, save_path:str=None, detections:Detections=None, image_id=None):
frame = torch.from_numpy(cv2.imread(path)).cuda().float()
batch = FastBaseTransform()(frame.unsqueeze(0))
if cfg.flow.warp_mode != 'none':
assert False, "Evaluating the image with a video-based model. If you believe this is a problem, please report a issue at GitHub, thanks."
extras = {"backbone": "full", "interrupt": False, "keep_statistics": False, "moving_statistics": None}
preds = net(batch, extras=extras)["pred_outs"]
img_numpy = prep_display(preds, frame, None, None, undo_transform=False)
if args.output_coco_json:
with timer.env('Postprocess'):
_, _, h, w = batch.size()
classes, scores, boxes, masks = \
postprocess(preds, w, h, crop_masks=args.crop, score_threshold=args.score_threshold)
with timer.env('JSON Output'):
boxes = boxes.cpu().numpy()
masks = masks.view(-1, h, w).cpu().numpy()
for i in range(masks.shape[0]):
# Make sure that the bounding box actually makes sense and a mask was produced
if (boxes[i, 3] - boxes[i, 1]) * (boxes[i, 2] - boxes[i, 0]) > 0:
detections.add_bbox(image_id, classes[i], boxes[i,:], scores[i])
detections.add_mask(image_id, classes[i], masks[i,:,:], scores[i])
if save_path is None:
img_numpy = img_numpy[:, :, (2, 1, 0)]
if save_path is None:
plt.imshow(img_numpy)
plt.title(path)
plt.show()
else:
cv2.imwrite(save_path, img_numpy)こちらを
def evalimage(net:Yolact, frame, save_path:str=None, detections:Detections=None, image_id=None):
frame = torch.from_numpy(frame).cuda().float()
batch = FastBaseTransform()(frame.unsqueeze(0))
extras = {"backbone": "full", "interrupt": False, "keep_statistics": False, "moving_statistics": None}
preds = net(batch, extras=extras)["pred_outs"]
img_numpy = prep_display(preds, frame, None, None, undo_transform=False)
cv2.imshow("frame", img_numpy)
cv2.waitKey(100)
上記のように変更します。
これを実行すると、Class1_def 内の画像全てを順に推論していきます。
ここまできたら、あとは cv2.VideoCapture() で読み込んだフレームを渡したりと、様々な応用が可能になります。
是非、様々な場面に応用してみてください。
おわりに
今回は軽量なインスタンスセグメンテーションである Yolact-Edge に関して、推論の方法と、実装の方法について説明しました。
Yolact-Edge の mobilenetv2 バックボーンを使用しましたが、他にもモデルがあるので精度が物足りない場合は、そちらを使用してみてください。
次回は detectron2 か OpenCV の便利なコードあたりを説明できたらと思います。



コメント