はじめに
前回は、オブジェクトのモデル情報を作成しました。

今回は、点群データの再構成に必要な ShapeNetCore を作成していきます。
前提条件
前提条件は以下の通りです。
- Windows11 (三次元モデルの準備にのみ使用)
- Ubuntu22 (モデル準備以降に使用)
- Python3.10.x
- CloudCompare
- open3d == 0.16.0
- こちらの記事を参考に 三次元モデルを作成していること
- シーンの作成が完了していること
- こちらの記事を参考に bop_toolkit_lib のインストールとプログラムの修正が完了していること
- マスクデータの作成が完了していること
- アノテーションデータの作成が完了していること
- オブジェクトのモデル情報の作成が完了していること
object-deformnet の準備
output_data/bop_data/lm/models_obj が存在していない場合は、output_data/bop_data/lm/models を output_data/bop_data/lm/models_obj に変更してください。
まずは、ShapeNetCore の作成に必要な github リポジトリを取得します。
cd maskeNOCS
git clone https://github.com/mentian/object-deformnet.git
cd object-deformnet
touch preprocess/shape_data_custom.py
ROOT=/path/to/object-deformnet
cd $ROOT/lib/nn_distance
python setup.py install --user
python3 -m pip install -U matplotlib
python3 -m pip install tqdm
touch ../makeNOCS/output_data/bop_data/lm/models_obj/obj_000001.txt
touch ../makeNOCS/output_data/bop_data/lm/models_obj/obj_000001_norm.txtobj_000001.txt の編集
前回作成した models_info.json を参考に、min_x, min_y, min_z を記入
7.236944e-02 3.276254e-02 5.148739e-03 ← min_x, min_y, min_z に -0.001 をかけたもの
-7.236944e-02 -3.276254e-02 -5.148739e-03 ← min_x, min_y, min_z に 0.001 をかけたものobj_000001_norm.txt の編集
CloudCompare でオブジェクトの ply ファイルを開いて、左中段あたりに記載されている Box Dimensionsを記入
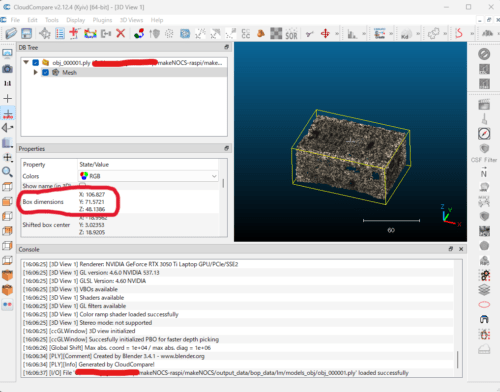
1.06827e-01
7.15721e-02
4.81386e-02ここの x, y, z の順番は、もしかしたら異なるかもしれません。
ShapeNetCore の作成
今作成した shape_data_custom.py を以下のように変更してください。
import os
import sys
import h5py
import glob
import numpy as np
import _pickle as cPickle
sys.path.append('../lib')
from lib.utils import sample_points_from_mesh
def save_nocs_model_to_file(obj_model_dir):
""" Sampling points from mesh model and normalize to NOCS.
Models are centered at origin, i.e. NOCS-0.5
"""
# CAMERA dataset
data_list = [
"000001"
]
for subset in ['train', 'val']:
camera = {}
for synsetId in data_list:
path_to_mesh_model = os.path.join(obj_model_dir, "obj_{}.obj".format(synsetId))
model_points = sample_points_from_mesh(path_to_mesh_model, 1024, fps=True, ratio=3)
# flip z-axis in CAMERA
model_points = model_points * np.array([[1.0, 1.0, -1.0]])
camera[synsetId] = model_points
with open(os.path.join(obj_model_dir, 'camera_{}.pkl'.format(subset)), 'wb') as f:
cPickle.dump(camera, f)
# Real dataset
for subset in ['real_train', 'real_test']:
real = {}
inst_list = glob.glob(os.path.join(obj_model_dir, '*.obj'))
for inst_path in inst_list:
instance = os.path.basename(inst_path).split('.')[0]
bbox_file = inst_path.replace('.obj', '.txt')
bbox_dims = np.loadtxt(bbox_file)
scale = np.linalg.norm(bbox_dims)
model_points = sample_points_from_mesh(inst_path, 1024, fps=True, ratio=3)
model_points /= scale
real[instance] = model_points
with open(os.path.join(obj_model_dir, '{}.pkl'.format(subset)), 'wb') as f:
cPickle.dump(real, f)
def save_model_to_hdf5(obj_model_dir, n_points, fps=False, include_distractors=False, with_normal=False):
""" Save object models (point cloud) to HDF5 file.
Dataset used to train the auto-encoder.
Only use models from ShapeNetCore.
Background objects are not inlcuded as default. We did not observe that it helps
to train the auto-encoder.
"""
catId_to_synsetId = {
1: '000001'
}
distractors_synsetId = [
"00000001"
]
# read all the paths to models
print('Sampling points from mesh model ...')
if with_normal:
train_data = np.zeros((3000, n_points, 6), dtype=np.float32)
val_data = np.zeros((500, n_points, 6), dtype=np.float32)
else:
train_data = np.zeros((3000, n_points, 3), dtype=np.float32)
val_data = np.zeros((500, n_points, 3), dtype=np.float32)
train_label = []
val_label = []
train_count = 0
val_count = 0
# CAMERA
for subset in ['train', 'val']:
for catId in [1]:
path_to_mesh_model = os.path.join(obj_model_dir, "obj_{}.obj".format(catId_to_synsetId[catId]))
model_points = sample_points_from_mesh(path_to_mesh_model, n_points, with_normal, fps=fps, ratio=2)
model_points = model_points * np.array([[1.0, 1.0, -1.0]])
if subset == 'train':
train_data[train_count] = model_points
train_label.append(catId)
train_count += 1
else:
val_data[val_count] = model_points
val_label.append(catId)
val_count += 1
# distractors
if include_distractors:
for synsetId in distractors_synsetId:
path_to_mesh_model = os.path.join(obj_model_dir, "obj_{}.obj".format(synsetId))
model_points = sample_points_from_mesh(path_to_mesh_model, n_points, with_normal, fps=fps, ratio=2)
# TODO: check whether need to flip z-axis, currently not used
model_points = model_points * np.array([[1.0, 1.0, -1.0]])
if subset == 'train':
train_data[train_count] = model_points
train_label.append(0)
train_count += 1
else:
val_data[val_count] = model_points
val_label.append(0)
val_count += 1
# Real
for subset in ['real_train', 'real_test']:
path_to_mesh_models = glob.glob(os.path.join(obj_model_dir, '*.obj'))
for inst_path in sorted(path_to_mesh_models):
instance = os.path.basename(inst_path).split('.')[0]
catId_txt = instance[-2:]
catId = int(catId_txt)
print(instance, catId_txt, catId)
# if instance.startswith('bottle'):
# catId = 1
# elif instance.startswith('bowl'):
# catId = 2
# elif instance.startswith('camera'):
# catId = 3
# elif instance.startswith('can'):
# catId = 4
# elif instance.startswith('laptop'):
# catId = 5
# elif instance.startswith('mug'):
# catId = 6
# elif instance.startswith('obj'):
# catId = 1
# else:
# raise NotImplementedError
model_points = sample_points_from_mesh(inst_path, n_points, with_normal, fps=fps, ratio=2)
bbox_file = inst_path.replace('.obj', '.txt')
bbox_dims = np.loadtxt(bbox_file)
model_points /= np.linalg.norm(bbox_dims)
# if catId == 6:
# shift = mug_meta[instance][0]
# scale = mug_meta[instance][1]
# model_points = scale * (model_points + shift)
if subset == 'real_train':
train_data[train_count] = model_points
train_label.append(catId)
train_count += 1
else:
val_data[val_count] = model_points
val_label.append(catId)
val_count += 1
num_train_instances = len(train_label)
num_val_instances = len(val_label)
assert num_train_instances == train_count
assert num_val_instances == val_count
train_data = train_data[:num_train_instances]
val_data = val_data[:num_val_instances]
train_label = np.array(train_label, dtype=np.uint8)
val_label = np.array(val_label, dtype=np.uint8)
print('{} shapes found in train dataset'.format(num_train_instances))
print('{} shapes found in val dataset'.format(num_val_instances))
# write to HDF5 file
print('Writing data to HDF5 file ...')
if with_normal:
filename = 'ShapeNetCore_{}_with_normal.h5'.format(n_points)
else:
filename = 'ShapeNetCore_{}.h5'.format(n_points)
hfile = h5py.File(os.path.join(obj_model_dir, filename), 'w')
train_dataset = hfile.create_group('train')
train_dataset.attrs.create('len', num_train_instances)
train_dataset.create_dataset('data', data=train_data, compression='gzip', dtype='float32')
train_dataset.create_dataset('label', data=train_label, compression='gzip', dtype='uint8')
val_dataset = hfile.create_group('val')
val_dataset.attrs.create('len', num_val_instances)
val_dataset.create_dataset('data', data=val_data, compression='gzip', dtype='float32')
val_dataset.create_dataset('label', data=val_label, compression='gzip', dtype='uint8')
hfile.close()
if __name__ == '__main__':
obj_model_dir = '/path/to/makeNOCS/output_data/bop_data/lm/models_obj'
# Save ground truth models for training deform network
save_nocs_model_to_file(obj_model_dir)
# Save models to HDF5 file for training the auto-encoder.
save_model_to_hdf5(obj_model_dir, n_points=4096, fps=False)
# Save nmodels to HDF5 file, which used to generate mean shape.
save_model_to_hdf5(obj_model_dir, n_points=2048, fps=True)
上記を実行します。
cd makeNOCS/object-deformnet
python3 -m preprocess.shape_data_custom実行が完了すると、makeNOCS/output_data/bop_data/lm/models_obj に ShapeNetCore_2048.h5, ShapeNetCore_4096.h5 が作成されます。
cd makeNOCS/output_data/bop_data/lm/models_obj
mkdir external
mv ShapeNetCore_2048.h5 external/external フォルダを作成して、ShapeNetCore_2048.h5 を移動しておきます。
プログラム説明
shape_data_custom.py について説明していきます。
import os
import sys
import h5py
import glob
import numpy as np
import _pickle as cPickle
sys.path.append('../lib')
from lib.utils import sample_points_from_mesh
def save_nocs_model_to_file(obj_model_dir):
""" Sampling points from mesh model and normalize to NOCS.
Models are centered at origin, i.e. NOCS-0.5
"""object-deformnet の lib フォルダを path に追加して import しています。
save_nocs_model_to_file 関数について説明していきます。
# CAMERA dataset
data_list = [
"000001"
]data_list は、対象となるオブジェクトの番号を記載します。今回は obj_000001.ply のみなので、”000001″ のみとなります。
for subset in ['train', 'val']:
camera = {}
for synsetId in data_list:
path_to_mesh_model = os.path.join(obj_model_dir, "obj_{}.obj".format(synsetId))
model_points = sample_points_from_mesh(path_to_mesh_model, 1024, fps=True, ratio=3)
# flip z-axis in CAMERA
model_points = model_points * np.array([[1.0, 1.0, -1.0]])
camera[synsetId] = model_points
with open(os.path.join(obj_model_dir, 'camera_{}.pkl'.format(subset)), 'wb') as f:
cPickle.dump(camera, f)object-deformnet の学習には train, val が必要なので、両方のデータを作成していきます。
今回は簡単化のために train も val も同じデータを使用します。
メッシュファイルを pointcloud に変換し、z方向のカメラを反転させてからpkl ファイルに変換することで、学習時のロード時間を短縮できるようにします。(なぜ flip するのか分かってないです…)
# Real dataset
for subset in ['real_train', 'real_test']:
real = {}
inst_list = glob.glob(os.path.join(obj_model_dir, '*.obj'))
for inst_path in inst_list:
instance = os.path.basename(inst_path).split('.')[0]
bbox_file = inst_path.replace('.obj', '.txt')
bbox_dims = np.loadtxt(bbox_file)
scale = np.linalg.norm(bbox_dims)
model_points = sample_points_from_mesh(inst_path, 1024, fps=True, ratio=3)
model_points /= scale
real[instance] = model_points
with open(os.path.join(obj_model_dir, '{}.pkl'.format(subset)), 'wb') as f:
cPickle.dump(real, f)CenterSnap や三次元姿勢推定のデータには、シミュレーション上のデータとリアルデータがあります。
リアルデータに関してはファインチューニングで使用します。
real_train, real_test がリアルデータとなります。
今回は obj_000001.txt を読み込んで、法線ベクトルを計算し、オブジェクトの点群をスケーリングします。
train, val と同様に pkl ファイルに保存しておくことでデータローダーを高速化します。
def save_model_to_hdf5(obj_model_dir, n_points, fps=False, include_distractors=False, with_normal=False):
""" Save object models (point cloud) to HDF5 file.
Dataset used to train the auto-encoder.
Only use models from ShapeNetCore.
Background objects are not inlcuded as default. We did not observe that it helps
to train the auto-encoder.
"""
catId_to_synsetId = {
1: '000001'
}
distractors_synsetId = [
"00000001"
]save_model_to_hdf5 について説明していきます。
catId_to_synsetId はカテゴリの ID です。今回は 1 つだけなので、000001 を入力しておきます。
distractors_synsetId は使用しませんので、無視して大丈夫です。
# read all the paths to models
print('Sampling points from mesh model ...')
if with_normal:
train_data = np.zeros((3000, n_points, 6), dtype=np.float32)
val_data = np.zeros((500, n_points, 6), dtype=np.float32)
else:
train_data = np.zeros((3000, n_points, 3), dtype=np.float32)
val_data = np.zeros((500, n_points, 3), dtype=np.float32)
train_label = []
val_label = []
train_count = 0
val_count = 0with_normal は特に指定しない限り False ですので無視します。
その他、必要な変数を初期化しておきます。
# CAMERA
for subset in ['train', 'val']:
for catId in [1]:まずはシミュレーションデータの train, val を作成していきます。
catId は [1] のみとなっていますが、使用するオブジェクトの種類に応じて [1, 2, 3, …] のように変更してください。
path_to_mesh_model = os.path.join(obj_model_dir, "obj_{}.obj".format(catId_to_synsetId[catId]))
model_points = sample_points_from_mesh(path_to_mesh_model, n_points, with_normal, fps=fps, ratio=2)
model_points = model_points * np.array([[1.0, 1.0, -1.0]])catId に対応する ply ファイルを読込みます。
メッシュファイルから点群に変更し、z軸のカメラを反転します。
if subset == 'train':
train_data[train_count] = model_points
train_label.append(catId)
train_count += 1
else:
val_data[val_count] = model_points
val_label.append(catId)
val_count += 1train, val それぞれでデータセットの数をカウントします。
# distractors
if include_distractors:
for synsetId in distractors_synsetId:
path_to_mesh_model = os.path.join(obj_model_dir, "obj_{}.obj".format(synsetId))
model_points = sample_points_from_mesh(path_to_mesh_model, n_points, with_normal, fps=fps, ratio=2)
# TODO: check whether need to flip z-axis, currently not used
model_points = model_points * np.array([[1.0, 1.0, -1.0]])
if subset == 'train':
train_data[train_count] = model_points
train_label.append(0)
train_count += 1
else:
val_data[val_count] = model_points
val_label.append(0)
val_count += 1include_distractors はデフォルトでは False なので無視します。
# Real
for subset in ['real_train', 'real_test']:
path_to_mesh_models = glob.glob(os.path.join(obj_model_dir, '*.obj'))
for inst_path in sorted(path_to_mesh_models):リアルデータに関して処理していきます。
処理していきますとは書きましたが、NOCSのリアルデータなど手作業で用意できるわけもないので、実際はシミュレーションデータを処理していきます。
instance = os.path.basename(inst_path).split('.')[0]
catId_txt = instance[-2:]
catId = int(catId_txt)
print(instance, catId_txt, catId)オブジェクトの ply のファイル名を取得します。
色々コメントアウトされている部分からの変更点となります。
model_points = sample_points_from_mesh(inst_path, n_points, with_normal, fps=fps, ratio=2)
bbox_file = inst_path.replace('.obj', '.txt')
bbox_dims = np.loadtxt(bbox_file)
model_points /= np.linalg.norm(bbox_dims)点群データを法線ベクトルでスケーリングします。
if subset == 'real_train':
train_data[train_count] = model_points
train_label.append(catId)
train_count += 1
else:
val_data[val_count] = model_points
val_label.append(catId)
val_count += 1real_train, val_train のデータをカウントします。
num_train_instances = len(train_label)
num_val_instances = len(val_label)
assert num_train_instances == train_count
assert num_val_instances == val_count
train_data = train_data[:num_train_instances]
val_data = val_data[:num_val_instances]
train_label = np.array(train_label, dtype=np.uint8)
val_label = np.array(val_label, dtype=np.uint8)
print('{} shapes found in train dataset'.format(num_train_instances))
print('{} shapes found in val dataset'.format(num_val_instances))カテゴリ数と画像データの数が同じだと、エラーで終了します。
カテゴリの数をターミナルに出力します。
# write to HDF5 file
print('Writing data to HDF5 file ...')
if with_normal:
filename = 'ShapeNetCore_{}_with_normal.h5'.format(n_points)
else:
filename = 'ShapeNetCore_{}.h5'.format(n_points)ShapeNetCore の h5 ファイルのファイル名を作成します。
hfile = h5py.File(os.path.join(obj_model_dir, filename), 'w')
train_dataset = hfile.create_group('train')
train_dataset.attrs.create('len', num_train_instances)
train_dataset.create_dataset('data', data=train_data, compression='gzip', dtype='float32')
train_dataset.create_dataset('label', data=train_label, compression='gzip', dtype='uint8')h5py を使用して新規の HDF5 ファイルをオープンします。
train グループを作成して、len, data, label の項目にデータを追加します。
val_dataset = hfile.create_group('val')
val_dataset.attrs.create('len', num_val_instances)
val_dataset.create_dataset('data', data=val_data, compression='gzip', dtype='float32')
val_dataset.create_dataset('label', data=val_label, compression='gzip', dtype='uint8')
hfile.close()同様に、val グループを作成して、len, data, label の項目にデータを追加します。
if __name__ == '__main__':
obj_model_dir = '/path/to/makeNOCS/output_data/bop_data/lm/models_obj'
# Save ground truth models for training deform network
save_nocs_model_to_file(obj_model_dir)
# Save models to HDF5 file for training the auto-encoder.
save_model_to_hdf5(obj_model_dir, n_points=4096, fps=False)
# Save nmodels to HDF5 file, which used to generate mean shape.
save_model_to_hdf5(obj_model_dir, n_points=2048, fps=True)最後に、メイン関数です。
コメントに書いてある通り、n_points=4096 を AutoEncoder の学習に使用し、n_points=2048 を mean_shape の計算に使用します。
おわりに
今回はここまでとします。
まだまだこれから object-deformnet 関係の処理が続きます。
次回は、AutoEncoder の計算に必要なもうひとつの前処理について説明していきます。
もしかしたら、単純な形状であれば、この AutoEncoder の学習は不要なのかもしれません。


コメント