はじめに
前回は CenterSnap を学習させる方法について説明しました。
今回は学習したモデルで推論する方法について説明します。
前提条件
前提条件は以下の通りです。
- Windows11 (三次元モデルの準備にのみ使用)
- Ubuntu22 (モデル準備以降に使用)
- Python3.10.x
- CloudCompare
- open3d == 0.16.0
- こちらの記事を参考に 三次元モデルを作成していること
- シーンの作成が完了していること
- こちらの記事を参考に bop_toolkit_lib のインストールとプログラムの修正が完了していること
- マスクデータの作成が完了していること
- アノテーションデータの作成が完了していること
- オブジェクトのモデル情報の作成が完了していること
- ShapeNetCore の HDF5 ファイルの作成が完了していること
- object-deformnet 用の中間ファイル作成が完了していること
- CenterSnap 用の中間ファイルの作成が完了していること
- CenterSnap の学習が完了していること
推論プログラム
cd makeNOCS/CenterSnap
touch inference_demo.pyinference_demo.py を以下のようにしてください。
# -*- coding: utf-8 -*-
import argparse
import pathlib
import cv2
import numpy as np
import torch
import torch.nn.functional as F
import open3d as o3d
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
import os
import time
import pytorch_lightning as pl
import _pickle as cPickle
import os, sys
sys.path.append('CenterSnap')
from simnet.lib.net import common
from simnet.lib import camera
from simnet.lib.net.panoptic_trainer import PanopticModel
from simnet.lib.net.models.auto_encoder import PointCloudAE
from utils.nocs_utils import load_img_NOCS, create_input_norm
from utils.viz_utils import depth2inv, viz_inv_depth
from utils.transform_utils import get_gt_pointclouds, transform_coordinates_3d, calculate_2d_projections
from utils.transform_utils import project
from utils.viz_utils import save_projected_points, draw_bboxes, line_set_mesh, display_gird, draw_geometries, show_projected_points
"""## 1. Instantiate CenterSnap Model"""
sys.argv = ['', '@configs/net_config.txt']
parser = argparse.ArgumentParser(fromfile_prefix_chars='@')
common.add_train_args(parser)
app_group = parser.add_argument_group('app')
app_group.add_argument('--app_output', default='inference', type=str)
app_group.add_argument('--result_name', default='centersnap_nocs', type=str)
app_group.add_argument('--data_dir', default='../output_data/bop_data/lm', type=str)
hparams = parser.parse_args()
min_confidence = 0.50
use_gpu=True
hparams.checkpoint = 'results/train/_ckpt_epoch_59009.ckpt'
# hparams.checkpoint = 'results/train/CenterSnap_TrainSynthetic/epoch=8009.ckpt'
model = PanopticModel(hparams, 0, None, None)
model.eval()
if use_gpu:
model.cuda()
data_path = open(os.path.join(hparams.data_dir, 'Real', 'test_list_all.txt')).read().splitlines()
_CAMERA = camera.NOCS_Real()
def get_auto_encoder(model_path):
emb_dim = 128
n_pts = 2048
ae = PointCloudAE(emb_dim, n_pts)
ae.cuda()
ae.load_state_dict(torch.load(model_path))
ae.eval()
return ae
"""## 2. Perform inference using NOCS Real Subset"""
#num from 0 to 3 (small subset of data)
num = 4
# img_full_path = os.path.join(hparams.data_dir, 'Real', data_path[num])
# img_vis = cv2.imread(img_full_path + '_color.png')
img_full_path = os.path.join(hparams.data_dir, 'Real')
basename = os.path.basename(data_path[num])
color_path = img_full_path + "/test/000000/color/" + basename
img_vis = cv2.imread(img_full_path + "/test/000000/color/" + basename)
depth_full_path = hparams.data_dir + "/camera_full_depths/" + basename[:-4] + ".png"
if not os.path.exists(color_path):
print("no image", color_path)
sys.exit()
if not os.path.exists(depth_full_path):
print("no depth", depth_full_path)
sys.exit()
left_linear, depth, actual_depth = load_img_NOCS(color_path, depth_full_path)
input = create_input_norm(left_linear, depth)[None, :, :, :]
auto_encoder_path = os.path.join(hparams.data_dir, 'auto_encoder_model', 'model_200.pth')
ae = get_auto_encoder(auto_encoder_path)
if use_gpu:
input = input.to(torch.device('cuda:0'))
_, _, _ , pose_output = model.forward(input)
with torch.no_grad():
latent_emb_outputs, abs_pose_outputs, peak_output, _, _ = pose_output.compute_pointclouds_and_poses(min_confidence,is_target = False)
print(len(abs_pose_outputs))
for j in range(len(abs_pose_outputs)):
# xyz_axis = 0.3*np.array([[0, 0, 0], [0, 0, 1], [0, 1, 0], [1, 0, 0]]).transpose()
xyz_axis = 0.3*np.array([[0, 0, 0], [0, 0, 1], [0, 1, 0], [1, 0, 0]]).transpose()
sRT = abs_pose_outputs[j].camera_T_object @ abs_pose_outputs[j].scale_matrix
transformed_axes = transform_coordinates_3d(xyz_axis, sRT)
projected_axes = calculate_2d_projections(transformed_axes, _CAMERA.K_matrix[:3,:3])
# print(sRT, transformed_axes, projected_axes)
"""### 2.1 Visualize Peaks output and Depth output"""
display_gird(img_vis, depth, peak_output)
"""## 2.2 Decode shape from latent embeddings"""
write_pcd = False
rotated_pcds = []
points_2d = []
box_obb = []
axes = []
colors_array = []
boxes = []
for j in range(len(latent_emb_outputs)):
emb = latent_emb_outputs[j]
emb = latent_emb_outputs[j]
emb = torch.FloatTensor(emb).unsqueeze(0)
emb = emb.cuda()
_, shape_out = ae(None, emb)
shape_out = shape_out.cpu().detach().numpy()[0]
rotated_pc, rotated_box, _ = get_gt_pointclouds(abs_pose_outputs[j], shape_out, camera_model = _CAMERA)
pcd = o3d.geometry.PointCloud()
pcd.points = o3d.utility.Vector3dVector(rotated_pc)
print("rotated_pc", rotated_pc.shape)
rotated_pcds.append(pcd)
pcd.paint_uniform_color((1.0, 0.0, 0.0))
colors_array.append(pcd.colors)
mesh_frame = o3d.geometry.TriangleMesh.create_coordinate_frame(size=0.1, origin=[0, 0, 0])
T = abs_pose_outputs[j].camera_T_object
mesh_frame = mesh_frame.transform(T)
rotated_pcds.append(mesh_frame)
cylinder_segments = line_set_mesh(rotated_box)
for k in range(len(cylinder_segments)):
rotated_pcds.append(cylinder_segments[k])
points_mesh = camera.convert_points_to_homopoints(rotated_pc.T)
points_2d_mesh = project(_CAMERA.K_matrix, points_mesh)
points_2d_mesh = points_2d_mesh.T
points_2d.append(points_2d_mesh)
#2D output
points_obb = camera.convert_points_to_homopoints(np.array(rotated_box).T)
points_2d_obb = project(_CAMERA.K_matrix, points_obb)
points_2d_obb = points_2d_obb.T
box_obb.append(points_2d_obb)
xyz_axis = 0.3*np.array([[0, 0, 0], [0, 0, 1], [0, 1, 0], [1, 0, 0]]).transpose()
sRT = abs_pose_outputs[j].camera_T_object @ abs_pose_outputs[j].scale_matrix
transformed_axes = transform_coordinates_3d(xyz_axis, sRT)
projected_axes = calculate_2d_projections(transformed_axes, _CAMERA.K_matrix[:3,:3])
axes.append(projected_axes)
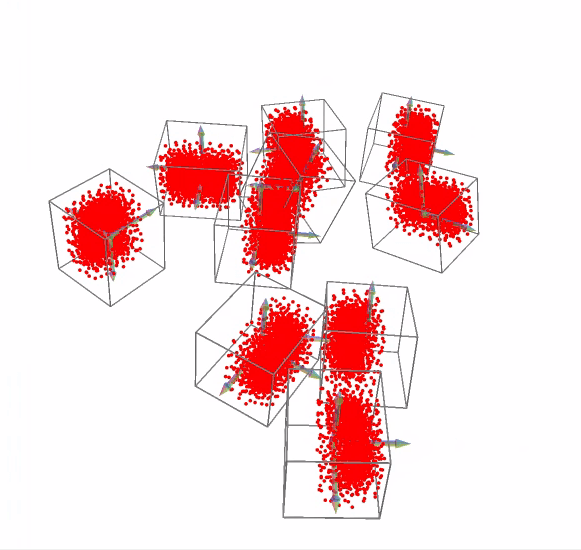
draw_geometries(rotated_pcds)
"""## 2.3 Project 3D Pointclouds and 3D bounding boxes on 2D image"""
color_img = np.copy(img_vis)
print(color_img.shape)
projected_points_img = show_projected_points(color_img, points_2d)
colors_box = [(63, 237, 234)]
im = np.array(np.copy(img_vis)).copy()
for k in range(len(colors_box)):
for points_2d, axis in zip(box_obb, axes):
points_2d = np.array(points_2d)
im = draw_bboxes(im, points_2d, axis, colors_box[k])
plt.gca().invert_yaxis()
plt.axis('off')
plt.imshow(im[...,::-1])
plt.show()
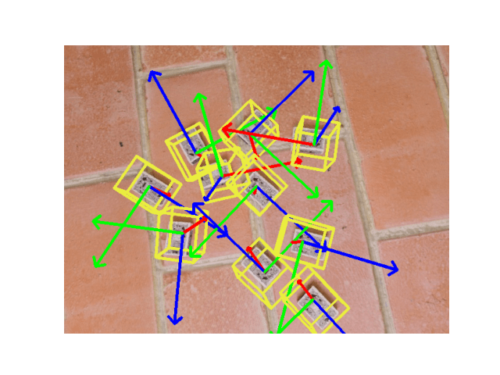
上記を実行すると、以下のような画像が得られます。
results/inference フォルダにも保存されます。


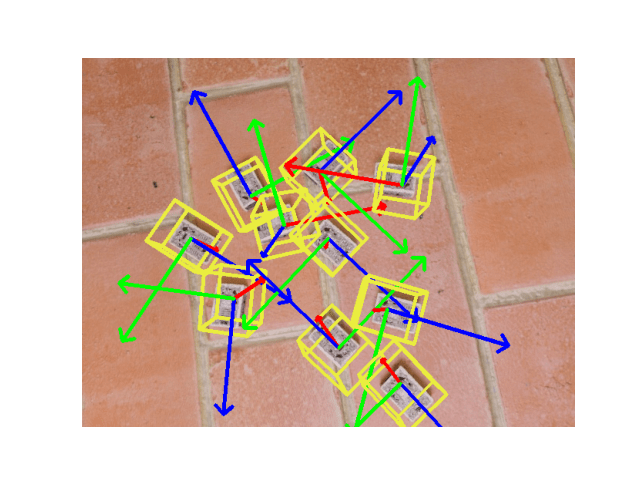
ラズパイのうち一つだけ天地が逆さになっていますが、良しとします。
おわりに
今回で CenterSnap は終わりとします。
本当は RealSense から取得したデータを使って推論したかったのですが、うまく推論することができませんでした。
次回からは別の方法で点群処理を実施していきます。

コメント