
はじめに
前回は ind_knn_ad で streamlit を使用せず学習及び推論を実行する方法について説明しました。

今回は、推論に使用したコードと、ハイパーパラメータを調整した際の結果について説明します。
前提条件
前提条件は以下の通りです。
- python3.9
- torch == 1.12.1+cu113
ind_knn_ad の github はこちらです。
demo.py の説明
まずはコードを再掲します。
from models import SPADE, PaDiM, PatchCore
from data import MVTecDataset
import cv2
import torch
import numpy as np
from torchvision import transforms
from torch import tensor
IMAGENET_MEAN = tensor([.485, .456, .406])
IMAGENET_STD = tensor([.229, .224, .225])
SIZE = 224
model = SPADE(k=11, backbone_name="wide_resnet50_2")
# model = PaDiM(d_reduced=150, backbone_name="wide_resnet50_2")
# model = PatchCore(f_coreset=.10, backbone_name="wide_resnet50_2")
train_ds, test_ds = MVTecDataset("custom", SIZE).get_dataloaders()
# feed healthy dataset
model.fit(train_ds)
transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize(SIZE, interpolation=transforms.InterpolationMode.BICUBIC),
transforms.CenterCrop(SIZE),
transforms.ToTensor(),
transforms.Normalize(IMAGENET_MEAN, IMAGENET_STD)
])
# get predictions
good_frame = cv2.imread("./good.png")
good_frame = cv2.cvtColor(good_frame,cv2.COLOR_BGR2RGB)
good_x = transform(good_frame)
good_x = good_x.unsqueeze(0)
defect_frame = cv2.imread("./defect.png")
defect_frame = cv2.cvtColor(defect_frame,cv2.COLOR_BGR2RGB)
defect_x = transform(defect_frame)
defect_x = defect_x.unsqueeze(0)
print(good_x.shape, defect_x.shape)
model.eval()
with torch.no_grad():
img_lvl_anom_score, pxl_lvl_anom_score = model.predict(good_x)
print("good frame score is: ", img_lvl_anom_score)
img_lvl_anom_score, pxl_lvl_anom_score = model.predict(defect_x)
print("defect frame score is: ", img_lvl_anom_score)import
from models import SPADE, PaDiM, PatchCore
from data import MVTecDatasetオブジェクト化する際はここのインポート文を相対的に指定してください。
使用しない SPADE, PaDiM, PatchCore のどれかは削除しても問題ありません。
画像のパラメータ設定
IMAGENET_MEAN = tensor([.485, .456, .406])
IMAGENET_STD = tensor([.229, .224, .225])
SIZE = 224画像のパラメータを指定します。平均と標準偏差はいじらなくてもいいと思いますが、SIZE は条件によって切り替えてください。
メモリを大量に消費しますので、画像サイズには注意が必要です。
モデル選択
model = SPADE(k=11, backbone_name="wide_resnet50_2")
# model = PaDiM(d_reduced=150, backbone_name="wide_resnet50_2")
# model = PatchCore(f_coreset=.10, backbone_name="wide_resnet50_2")model 選択をします。それぞれのパラメータを調整した際の結果は後述します。
学習用データローダー作成
train_ds, test_ds = MVTecDataset("custom", SIZE).get_dataloaders()
# feed healthy dataset
model.fit(train_ds)datasets/custom フォルダ内を対象にデータローダーを作成します。
model.fit で学習します。
推論用 transform 作成
transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize(SIZE, interpolation=transforms.InterpolationMode.BICUBIC),
transforms.CenterCrop(SIZE),
transforms.ToTensor(),
transforms.Normalize(IMAGENET_MEAN, IMAGENET_STD)
])ToPILImage で opencv の画像(numpy.ndarray) から PIL 形式へ変換します。
CenterCrop は中心から切り出すだけなので取り入れてはいますが、不要です。
推論用画像の読込
# get predictions
good_frame = cv2.imread("./good.png")
good_frame = cv2.cvtColor(good_frame,cv2.COLOR_BGR2RGB)
good_x = transform(good_frame)
good_x = good_x.unsqueeze(0)
defect_frame = cv2.imread("./defect.png")
defect_frame = cv2.cvtColor(defect_frame,cv2.COLOR_BGR2RGB)
defect_x = transform(defect_frame)
defect_x = defect_x.unsqueeze(0)PIL と opencv では 色の配列が異なるので、cvtColor で変換します。
その後、transform で推論用に変換します。
この状態では([3, 224, 224]) となっているのですが、([1, 3, 224, 224]) に変換する必要があるので unsqueeze で変換します。
推論の実行
model.eval()
with torch.no_grad():
img_lvl_anom_score, pxl_lvl_anom_score = model.predict(good_x)model.eval() でモデルを評価用に切り替えます。
その後、 with torch.no_grad() で推論時にパラメータが変更されないようにします。
SPADE のハイパーパラメータを変更
model = SPADE(k=11, backbone_name="wide_resnet50_2")この文の、k の数値を変化させてみます。
k = 100 の場合
100%|██████████| 1000/1000 [03:28<00:00, 4.80it/s]
torch.Size([1, 3, 224, 224]) torch.Size([1, 3, 224, 224])
good frame score is: tensor(7.4699)
defect frame score is: tensor(7.5025)k = 5 の場合
100%|██████████| 1000/1000 [03:15<00:00, 5.11it/s]
torch.Size([1, 3, 224, 224]) torch.Size([1, 3, 224, 224])
good frame score is: tensor(6.1383)
defect frame score is: tensor(6.2742)スコア自体が 1 ポイントほど高くなりましたが、good と defect の差は変わりませんでした。
PaDiM のハイパーパラメータを変更
model = PaDiM(d_reduced=150, backbone_name="wide_resnet50_2")d_reduced を調整します。
d_reduced = 150 の場合
100%|██████████| 1000/1000 [03:06<00:00, 5.37it/s]
PaDiM: (randomly) reducing 1792 dimensions to 150.
torch.Size([1, 3, 224, 224]) torch.Size([1, 3, 224, 224])
good frame score is: tensor(21.9047)
defect frame score is: tensor(37.7102)d_reduced = 350 の場合
100%|██████████| 1000/1000 [03:04<00:00, 5.42it/s]
PaDiM: (randomly) reducing 1792 dimensions to 350.
torch.Size([1, 3, 224, 224]) torch.Size([1, 3, 224, 224])
good frame score is: tensor(34.3105)
defect frame score is: tensor(38.7452)d_reduced を大きくすると、good と defect の差が小さくなりました。
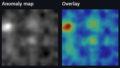
このことから、ハイパーパラメータは微調整する必要がありそうです。
おわりに
今回は、学習コードの説明とハイパーパラメータを調整した結果について説明しました。
PatchCore に関しては、皆さんで試してみていただければと思います。
次回はオブジェクト化についてのコードを用意できればと思いますが非常に複雑となるので、考えておきます。
コメント