
はじめに
前回の記事では、Yolov5 をオブジェクト化しました。

今回の記事では、推論コードについて説明します。
前提条件
前提条件は、以下の通りです。
- numpy>1.22.0, opencv-python>4.5.0, pytorch>1.8.0 がインストールされている(CPUとGPUはどちらでも問題ありません)
- Visual Studio Code がインストールされている
- コマンドはUbuntuのものですが、Windowsでもほとんど動作します(python3, pip3 → python, pip に置き換える必要があります)
推論用のコードを再掲
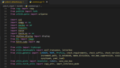
import numpy as np
import cv2
import torch
from yolov5_object.models.common import DetectMultiBackend
from yolov5_object.utils.augmentations import letterbox
from yolov5_object.utils.general import non_max_suppression
# ======================= yolov5 ========================= #
frame = cv2.imread("./output.png")
h, w, _ = frame.shape
device = torch.device("cuda")
model = DetectMultiBackend("./yolov5/yolov5s.pt", device=device, dnn=False, data='./yolov5/data/coco128.yaml', fp16=True)
stride, names, pt = model.stride, model.names, model.pt
conf_thres = 0.45
iou_thres = 0.25
classes = None
# Padded resize
img = letterbox(frame, 640, stride=stride, auto=True)[0]
# Convert
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
im = torch.from_numpy(img).to(device)
im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim
pred = model(im, augment=False, visualize=False)
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, False, max_det=50)
pred_cpu = pred[0][0].cpu().detach().numpy()
index = int(pred_cpu[5])
print(pred_cpu, index, names[index])推論用のコード説明
# ======================= yolov5 ========================= #
frame = cv2.imread("./output.png")
h, w, _ = frame.shape
device = torch.device("cuda")opencv で画像を読み込み、画像のサイズを取得します。
GPU を使用しない場合は torch.device(“cpu”) としてください。
model = DetectMultiBackend("./yolov5/yolov5s.pt", device=device, dnn=False, data='./yolov5/data/coco128.yaml', fp16=True)Yolov5 のモデルを構築します。今回は yolov5s.pt, coco128.yaml を基に検出していきます。
dnn は dnnモジュールを使用しないので False、half は推論が早くなるので True とします。
coco128.yaml について
coco128.yaml は、yolov5_object > data 内にあります。検出した際のクラスインデックスとラベルを紐づけるデータです。
今回はマウスを検出したいので、64 というインデックスが出力されれば成功です。
stride, names, pt = model.stride, model.names, model.ptDetectMultiBackend() で作成した model から、ストライド、names(=coco128.yaml), pt(pytorch用のモデルかどうかのbool変数) を取得しておきます。
# Padded resize
img = letterbox(frame, 640, stride=stride, auto=True)[0]letterbox は opencv で読み込んだ画像を推論用のサイズに変換するために、ストライドを適用します。1次元増えて帰ってくるので、[0] で画像部分のみ取り出します。
# Convert
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)img.transpose で、opencv の画像から PILフォーマット の画像に変換します。
np.ascontiguousarray() で、numpy 配列に変換します。
im = torch.from_numpy(img).to(device)
im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim変換した numpy を torch.Tensor に変換します。
画素値を 0 – 255 から 0 – 1 の半精度浮動小数に変換します。
[ch, h, w] → [batch, ch, h, w] のように、バッチの次元を追加します。
pred = model(im, augment=False, visualize=False)ここは PyTorch のデフォルトの推論方法と同じです。
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, False, max_det=50)non_max_suppression で、bbox の重複を解消します。
max_det = 50 は、最大検出数を指定します。
pred_cpu = pred[0][0].cpu().detach().numpy()
index = int(pred_cpu[5])
print(pred_cpu, index, names[index])GPU 上の検出結果を CPU 上へとコピーします。
names[index] で、coco128.yaml のラベル名を取得することができます。
推論結果の見方に関してはこちらをご参考ください。
おわりに
今回は、Yolov5 をオブジェクト化して推論するためのコードの説明をしました。
こちらのコードを使用するだけで、様々な検出に組み込むことが可能になります。
次回は、試しに open3d の pointcloud と連携させてみます。


コメント