はじめに
前回はインスタンスセグメンテーションの学習方法について、Detectron2 を使用して説明しました。

今回はインスタンスセグメンテーションモデルで推論を実行し、その結果の見方や、独自のシステムに落とし込む際のコードについて説明します。
前提条件
前提条件は以下の通りです。
- Detectron2 がインストールされている
- 前回の記事を参考に、カスタムデータの学習が終わっている
この記事の環境は以下の通りです。
- detectron2 == 0.6
- torch == 1.11.0+cu113
- cv2 == 4.5.5-dev
- numpy == 1.23.3
推論用コードの説明
推論用コードを作成していきます。
cd ~/detectron2-dev/detectron2-train
touch detectron_inference.py
code .VSCode 上で以下のコードを入力してください。
import os
import cv2
from detectron2.engine import DefaultPredictor
from detectron2.config import get_cfg
from detectron2.utils.visualizer import Visualizer
from detectron2.data import DatasetCatalog, MetadataCatalog
from detectron2.data.datasets import register_coco_instances
from detectron2.utils.visualizer import ColorMode
from detectron2 import model_zoo
import glob
import time
cfg = get_cfg()
cfg.OUTPUT_DIR = './output'
cfg.CUDA = 'cuda:0'
register_coco_instances("train", {}, "./images_annotation-coco/annotations.json", "./images_annotation-coco")
metadata = MetadataCatalog.get("train")
dataset_dicts = DatasetCatalog.get("train")
print(metadata)
print()
print(dataset_dicts)
cfg.merge_from_file(model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"))
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 3
cfg.MODEL.WEIGHTS = os.path.join(cfg.OUTPUT_DIR, "model_final.pth")
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5
predictor = DefaultPredictor(cfg)
# inference
filepath = glob.glob("./images_annotation-coco/JPEGImages/*.jpg")
i = 0
for d in filepath:
start = time.time()
print(d)
im = cv2.imread(d)
outputs = predictor(im) # format is documented at https://detectron2.readthedocs.io/tutorials/models.html#model-output-format
v = Visualizer(im[:, :, ::-1],
metadata=metadata,
scale=1,
instance_mode=ColorMode.IMAGE_BW # remove the colors of unsegmented pixels. This option is only available for segmentation models
)
out = v.draw_instance_predictions(outputs["instances"].to("cpu"))
img = out.get_image()[:, :, ::-1]
print(time.time()-start)
cv2.imshow("frame", img)
cv2.waitKey(0)
if i < 3:
i += 1
else:
break
cv2.destroyAllWindows()コードの説明をしていきます。
cfg = get_cfg()
cfg.OUTPUT_DIR = './output'
cfg.CUDA = 'cuda:0'cfg = get_cfg() で get_cfg() クラスをインスタンス化します。
cfg.OUTPUT_DIR は訓練データの出力フォルダを指定しますが、今回は推論モデルを読み込むために使用します。
register_coco_instances("train", {}, "./images_annotation-coco/annotations.json", "./images_annotation-coco")
metadata = MetadataCatalog.get("train")
dataset_dicts = DatasetCatalog.get("train")非常に便利な register_coco_instances を今回も使用します。
ここから、クラス名や metadata を使用して描画します。
cfg.merge_from_file(model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"))
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 3
cfg.MODEL.WEIGHTS = os.path.join(cfg.OUTPUT_DIR, "model_final.pth")
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5
predictor = DefaultPredictor(cfg)基本的に学習時と同じ cfg の設定で大丈夫です。
cfg.MODEL.WEIGHTS は前回作成した model_final.pth を指定します。
filepath = glob.glob("./images_annotation-coco/JPEGImages/*.jpg")今回は学習に使用した画像を対象に解析を実行しますので、glob で JPEGImages 内の jpg ファイルを読み込みます。
im = cv2.imread(d)
outputs = predictor(im)opencv で読み込んだ画像をそのまま DefaultPredictor のインスタンスに投げてやれば、推論は完了します。PyTorch の model(image) と同じですね。
v = Visualizer(im[:, :, ::-1],
metadata=metadata,
scale=1,
instance_mode=ColorMode.IMAGE_BW # remove the colors of unsegmented pixels. This option is only available for segmentation models
)
out = v.draw_instance_predictions(outputs["instances"].to("cpu"))Detectron2 の Visualizer 関数は、描画に関してのヘルパーとなります。
結果を確認したいときは、draw_instance_predictions 関数を使用して簡単に確認することができます。
残りのコードは割愛します。
推論の実行
早速、detectron_inference.py を実行していきます。
python3 detectron_inference.py以下のような結果が出力されます。


わずか20分程度の学習なのにしっかり学習できています。
その分、モデル容量が重く、推論も少し時間がかかっています。
RTX3050 4GB で 0.3s 程度の推論時間です。
output の確認
結果を画像で確認する方法については説明したので、次は predictor(im) の出力結果を確認します。
print() で出力すると、以下のような内容になっています。
{'instances': Instances(
num_instances=1, image_height=512, image_width=512,
fields=[pred_boxes: Boxes(tensor([[191.3941, 397.1920, 292.2796, 451.4123]], device='cuda:0')),
scores: tensor([0.9398], device='cuda:0'), pred_classes: tensor([2], device='cuda:0'),
pred_masks: tensor([[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]]], device='cuda:0')])}‘instances’ はインスタンスセグメンテーションの結果となります。
クラスラベルの取得
予測したクラスラベルだけ知りたいときは
outputs['instances'].to("cpu").pred_classes.numpy()予測スコアの取得
予測スコアを知りたいときは
outputs['instances'].to("cpu").scores.numpy()バウンディングボックスの座標の取得
検出した矩形の点を知りたいときは
outputs['instances'].to("cpu").pred_boxes.tensor.detach().numpy()出力される矩形情報は [x0, y0, x1, y1] となります。
マスク領域の取得
検出したマスク領域を知りたいときは
print(outputs['instances'].to("cpu").pred_masks.numpy())で取得できます。
今回の場合、マスク領域の shape は (1, 512, 512) となります。
opencvで表示する場合は、(512, 512) に変換する必要があります。
以下のコードが、マスク表示のためのコードとなります。
im = cv2.imread(d)
mask = np.full(im.shape[:2], 255, dtype=im.dtype)
outputs = predictor(im)
mask_ = outputs['instances'].to("cpu").pred_masks.numpy()
mask_ = mask_.reshape([512,512])
mask[mask_==0] = mask_[mask_==0]以下のような画像を取得できます。
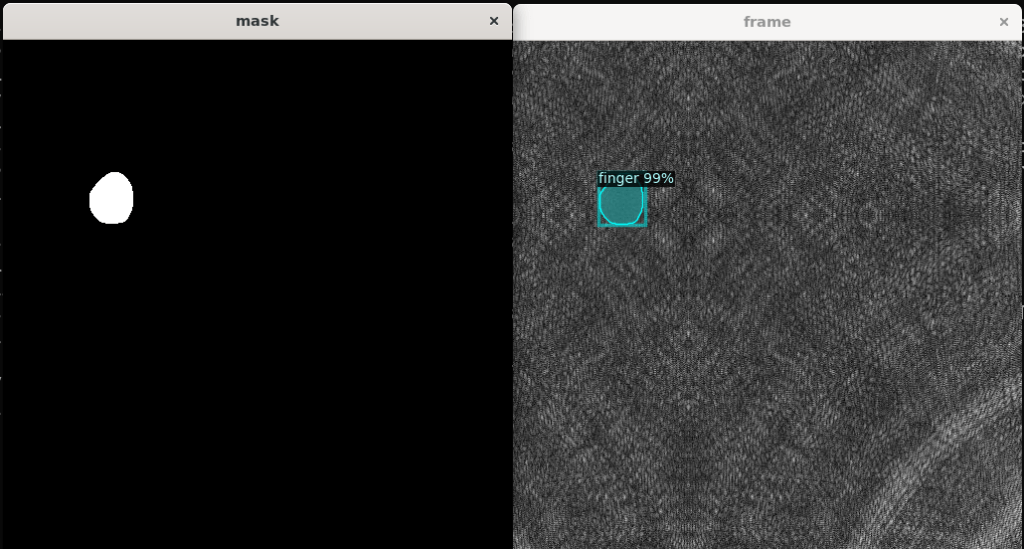
これを使用すれば、検出領域の重心や面積を求めることができます。
おわりに
今回は、Detectron2 のインスタンスセグメンテーションの推論方法について説明しました。
また、推論結果の確認方法やマスク領域の取り出し方法も説明しました。
これを使用すればロボットでピック&プレースや、ロボットの把持姿勢の算出ができるようになります。ROS2 と組み合わせると更に面白いことがたくさんできます。
次回は、Detectron2 の他の AIモデル について学習方法と推論方法を説明していきます。


コメント