
はじめに
以前の記事で紹介した Yolov5 で物体認識を行いました。
Yolov5 はどこに・何が映っているかを検出するAIでした。

今回はインスタンスセグメンテーションと呼ばれるピクセル単位で何が映っているかを解析できるAIである Yolact-Edge について、カスタムデータで学習する方法を説明します。
前提条件
前提条件は、以下の通りです。
- PyTorch > 1.9.x がインストールされている (1.8.x では動きません)
- GPU の学習環境 (Google Colabでも可)
ライブラリの不足でエラーが出る場合は、その都度インストールしてください。
Yolact-Edge の学習準備
Yolact-Edgeは軽量なインスタンスセグメンテーションを可能にします。
githubのページはこちらにあります。
まずは、Yolact-Edge をダウンロードします。
mkdir yolact-train
cd ~/yolact-train
git clone https://github.com/haotian-liu/yolact_edge.gitYolact-Edgeのgithubページを開きます。ページの中段あたりまでスクロールしてください。
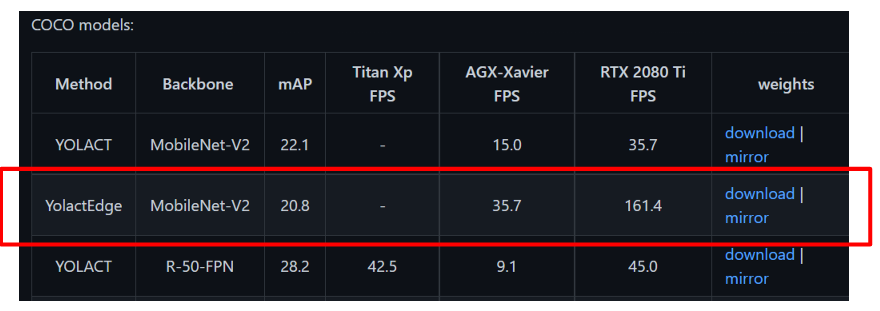
赤枠の download から、事前学習済みのモデルデータをダウンロードします。
次に、下段あたりまでスクロールしてください。
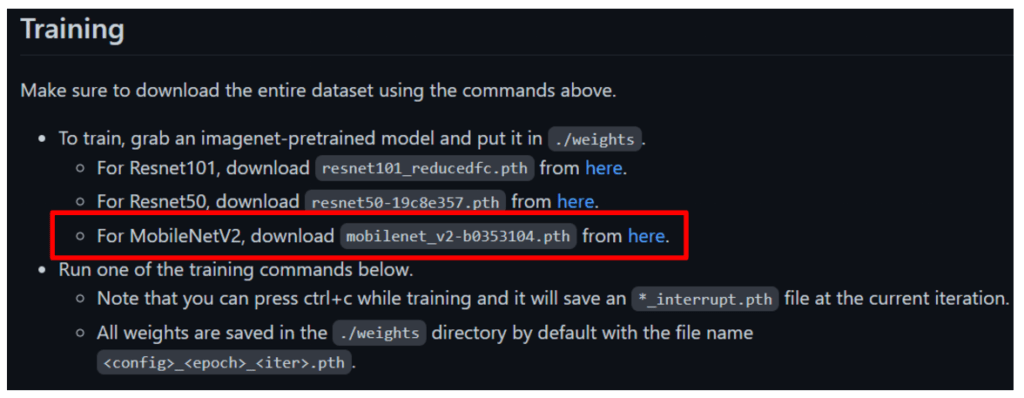
赤枠の部分の here から、学習用のモデルデータをダウンロードしてください。
mkdir weight今作成した yolact-train/weight フォルダにモデルデータを移動してください。
cd ~/yolact-train/weight
mv mobilenet_v2-b0353104.pth my_mobilenetv2_config_0_0.pthアノテーションの準備
yolact-edge のようなインスタンスセグメンテーションと Yolov5 のような物体認識では、アノテーション方法が異なります。
今回は labelme を使用します。こちらのページにあります。
cd ~/yolact-train
git clone -b v5.0.4 https://github.com/wkentaro/labelme.git
labelme以下のような画面が立ち上がれば成功です。
データは以前の Yolov5 の記事を使用します。
工業製品のデータセットです。
ダウンロード方法を再掲します。データセットの詳細はこちらにあります。
cd ~/yolact-train
mkdir images
cd images
wget https://conferences.mpi-inf.mpg.de/dagm/2007/Class1_def.zip
unzip Class1_def.zip
rm Class1_def.zip
wget https://conferences.mpi-inf.mpg.de/dagm/2007/Class2_def.zip
unzip Class2_def.zip
rm Class2_def.zip
mkdir images_annotationClass1_def, Class2_def から適当に15枚程度選択して、それぞれ images_annotation にコピーしてください。
今回は ファイル名が上書きされないように、Class1_def の 1.png ~ 15.png, Class2_def の 16.png ~ 30.png を images_annnotation にコピーしました。
labelmeでアノテーション
早速、アノテーションをしていきます。
cd yolact-train
touch images/classes.txtclasses.txt の中身は以下のようにします。
__ignore__
__background__
finger
scratch次に、labelme を起動します。
labelme --labels image/classes.txt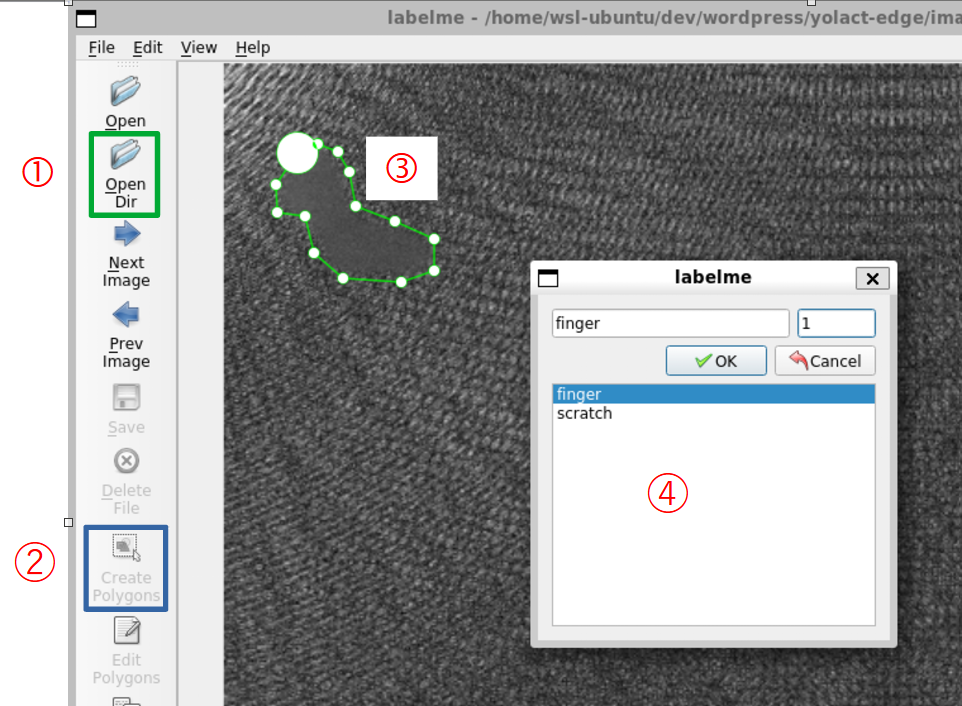
手順を説明します。
- ①を押して、images_annotation フォルダを選択します。
- 画像が labelme 上に表示されるので、②を押して、指紋部分を囲う③のようにクリックしていきます。
- 閉じた領域を作成すると、④の Window が表示されるので、finger を選択します。
- ④の右上には1を入力します。もし、finger が複数ある場合は1, 2, 3, … と入力します。
画像ごとに1, 2, 3, …と入力すれば大丈夫です。画像をまたいで連番にする必要はありません。 - Ctrl + S で保存します。.json ファイルが images_annotation に保存されます。
- この作業をimages_annotationフォルダの画像全てに実施します。
Yolact-Edge で学習できるようにアノテーションデータを変換する
ここまでできたら、あとは Yolact-Edge で学習できるようにアノテーションデータを変換します。
詳細はこちらのページに載っています。
COCO-format に変換します。
cd ~/yolact-train
python3 ./labelme/examples/instance_segmentation/labelme2coco.py images/images_annotation images/images_annotation-coco --labels images/classes.txt上記を実行すると、images/images_annotation-coco に、COCO-format のアノテーションデータが作成されます。
Yolact-Edge の学習準備②
ここまできたら、あとは Yolact-Edge をカスタムデータで学習できるようにプログラムを少し変更していきます。
まずは、VSCode で、ソースプログラムを開きます。
cd ~/yolact-train/yolact_edge
code .yolact_edge/yolact_edge/data/config.py を開いて、220行目の
flying_chairs_dataset = dataset_base.copy({
'name': 'FlyingChairs',
'trainval_info': './data/FlyingChairs/train_val.txt',
'trainval_images': './data/FlyingChairs/data/',
})の下に、以下を追加します。
my_dataset = dataset_base.copy({
'name': 'my_dataset',
'train_info': '../images/images_annotation-coco/annotations.json',
'train_images': '../images/images_annotation-coco',
'valid_info': '../images/images_annotation-coco/annotations.json',
'valid_images': '../images/images_annotation-coco',
'has_gt': True,
'class_names': ("finger", "scratch"),
})次に、895行目の
yolact_edge_mobilenetv2_config = yolact_edge_config.copy({
'name': 'yolact_edge_mobilenetv2',
'backbone': mobilenetv2_backbone
})この下に、以下を追加します。
my_mobilenetv2_config = yolact_edge_config.copy({
'name': 'yolact_edge_mobilenetv2',
'dataset': my_dataset,
'num_classes': len(my_dataset.class_names) + 1,
'backbone': mobilenetv2_backbone
})次に、yolact_edge/yolact_edge/data/coco.py を開き、42行目を変更します。
label_idx = self.label_map[label_idx] - 1
↓
label_idx = label_idx - 1以上で準備は完了です。
Yolact-Edge の学習
ようやく、学習を実行します。
cd ~/yolact-train/yolact_edge
python3 train.py --config=my_mobilenetv2_config --resume=../weights/my_mobilenetv2_config_0_0.pth --start_iter=0 --batch_size=4 --num_workers=0 --lr=0.001 --dataset=my_datasetを実行してください。
ModuleNotFoundError: No module named 'git'が表示された場合、
pip3 install gitpythonを実行してください。

上記画像のように、学習が始まります。10000イテレーション毎にモデルは保存されます。
半日程度(数時間でも結果は確認できます)学習させたら、Ctrl + C で学習を停止させてください。

最終的に、このような検証結果が表示されていると思います。
学習させたYolact-Edgeモデルの検証
続いて、学習結果を確認します。
その前に、eval.py の1276行目
convert_to_tensorrt(net, cfg, args, transform=BaseTransform())
をコメントアウトしてください。
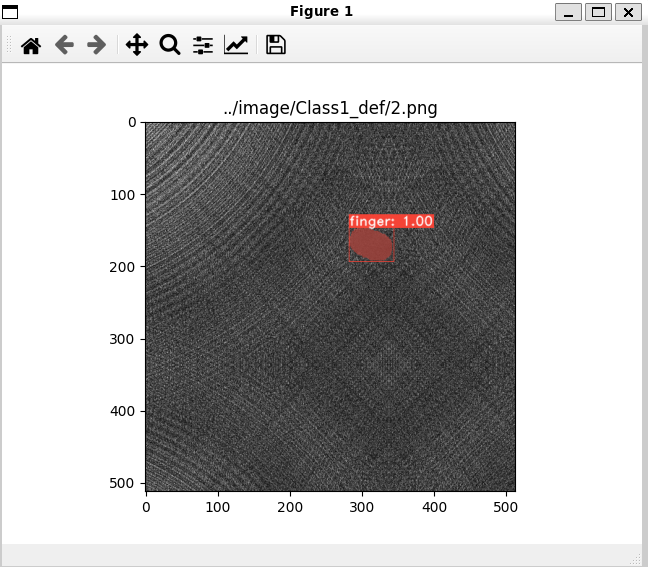
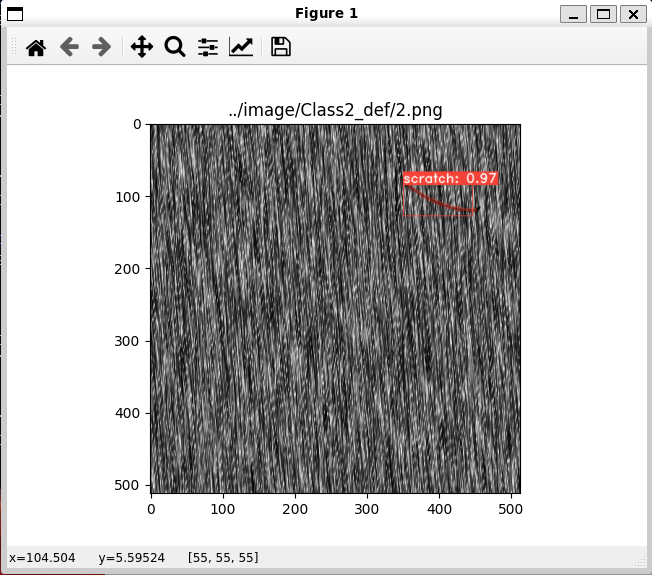
python3 eval.py --trained_model=weights/my_mobilenetv2_config_4285_30000.pth --score_threshold=0.45 --top_k=3 --image=../image/Class1_def/2.png --config=my_mobilenetv2_configtrained_model は、weightsフォルダに作成された .pth のパスを入力してください。
Class1_def/2.png と Class2_def/2.png で以下のような画像が表示されたら成功です。
補足
weight ファイルの名称について
weight ファイルの my_mobilenetv2_config_4285_30000.pth ですが、これは4285エポックで30000イテレーションを実行した結果です。
学習時のエラーについて
Yolact-Edge のようなインスタンスセグメンテーションは、学習に時間がかかります。また、メモリ消費量も大きいので学習時の引数には注意を払う必要がります。
特に注意しなければならないのは、学習率 (–lr) です。
適当に設定すると、損失が発散してしまいます。
その場合、以下のようなエラーが出ます。
../aten/src/ATen/native/cuda/Loss.cu:115: operator(): block: [13,0,0], thread: [95,0,0] Assertion `input_val >= zero && input_val <= one` failedRuntimeError: CUDA error: device-side assert triggeredこのようなエラーが出る場合、–lr を小さくしてください。
小さくしすぎると、学習は終わりませんので、微調整してください。
おわりに
今回はインスタンスセグメンテーションAIである Yolact-Edge の学習方法について説明しました。
これを使えば、どこに・何があるのか分かるとともに、ピクセル単位まで検出できるので、面積を出したり、重心を出すことが可能です。
ロボットピッキングもできるようになるので、使い道は豊富です。
次回は、Yolact-Edge の推論方法の詳細と、Yolact-Edge をオブジェクト化していこうと思います。



コメント