はじめに
前回は 3D-ResNets-PyTorch のデータローダー部分について説明しました。

今回は入力データをカスタムデータに置き換えられるように説明していきます。
github はこちらです。
前提条件
前提条件は以下の通りです。
- Python3.9
- torch == 1.13.0+cu117, torchvision == 0.14.0+cu117
- 作業は WSL2 で実施します
入力データの作成
まずは、入力データを作成していきます。
inference_custom.py に追記していきます。
inference_custom.py
import time
import json
from collections import defaultdict
import torch
import torch.nn.functional as F
from utils import AverageMeter
import cv2
from spatial_transforms import (Compose, Normalize, Resize, CenterCrop,
ToTensor, ScaleValue, PickFirstChannels)
def get_video_results(outputs, class_names, output_topk):
sorted_scores, locs = torch.topk(outputs,
k=min(output_topk, len(class_names)))
video_results = []
for i in range(sorted_scores.size(0)):
video_results.append({
'label': class_names[locs[i].item()],
'score': sorted_scores[i].item()
})
return video_results
def get_normalize_method(mean, std, no_mean_norm, no_std_norm):
if no_mean_norm:
if no_std_norm:
return Normalize([0, 0, 0], [1, 1, 1])
else:
return Normalize([0, 0, 0], std)
else:
if no_std_norm:
return Normalize(mean, [1, 1, 1])
else:
return Normalize(mean, std)
def inference(data_loader, model, result_path, class_names, no_average,
output_topk, opt):
print('inference')
spatial_transform = []
normalize = get_normalize_method(opt.mean, opt.std, opt.no_mean_norm,
opt.no_std_norm)
spatial_transform = [Resize(opt.sample_size)]
if opt.inference_crop == 'center':
spatial_transform.append(CenterCrop(opt.sample_size))
spatial_transform.append(ToTensor())
if opt.input_type == 'flow':
spatial_transform.append(PickFirstChannels(n=2))
spatial_transform.extend([ScaleValue(opt.value_scale), normalize])
spatial_transform = Compose(spatial_transform)
model.eval()
batch_time = AverageMeter()
data_time = AverageMeter()
results = {'results': defaultdict(list)}
end_time = time.time()
result_list = []
with torch.no_grad():
for i, (inputs, targets) in enumerate(data_loader):
data_time.update(time.time() - end_time)
from PIL import Image
video = []
clips = []
for i in range(1,17):
img = Image.open("../UCF101_images/UCF101/ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c01/image_{:05}.jpg".format(i))
video.append(img.convert('RGB'))
spatial_transform.randomize_parameters()
clip = [spatial_transform(img) for img in video]
clips.append(torch.stack(clip, 0).permute(1, 0, 2, 3))
print(len(clips), len(clips[0]), clips[0][0].shape, inputs[0][0].shape)
for i, j, k, l, m, n in zip(inputs[0][0], inputs[0][1], inputs[0][2], clips[0][0], clips[0][1], clips[0][2]):
ii = i.cpu().detach().numpy()
jj = j.cpu().detach().numpy()
kk = k.cpu().detach().numpy()
ll = l.cpu().detach().numpy()
mm = m.cpu().detach().numpy()
nn = n.cpu().detach().numpy()
cv2.imshow("input1", ii)
cv2.imshow("input2", jj)
cv2.imshow("input3", kk)
cv2.imshow("clip1", ll)
cv2.imshow("clip2", mm)
cv2.imshow("clip3", nn)
cv2.waitKey(0)
a
video_ids, segments = zip(*targets)
outputs = model(inputs)
outputs = F.softmax(outputs, dim=1).cpu()
for j in range(outputs.size(0)):
results['results'][video_ids[j]].append({
'segment': segments[j],
'output': outputs[j]
})
sorted_scores, locs = torch.topk(torch.mean(outputs, dim=0),
k=min(output_topk, len(class_names)))
result_list.append([sorted_scores.item(), locs.item()])
# for r in result_list:
# print(r)
batch_time.update(time.time() - end_time)
end_time = time.time()
print('[{}/{}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Data {data_time.val:.3f} ({data_time.avg:.3f})\t'.format(
i + 1,
len(data_loader),
batch_time=batch_time,
data_time=data_time))
inference_results = {'results': {}}
if not no_average:
for video_id, video_results in results['results'].items():
video_outputs = [
segment_result['output'] for segment_result in video_results
]
video_outputs = torch.stack(video_outputs)
average_scores = torch.mean(video_outputs, dim=0)
inference_results['results'][video_id] = get_video_results(
average_scores, class_names, output_topk)
with result_path.open('w') as f:
json.dump(inference_results, f)
追加した部分の説明をします。
11 -12 行目
from spatial_transforms import (Compose, Normalize, Resize, CenterCrop,
ToTensor, ScaleValue, PickFirstChannels)spatial_transforms.py から、各種 Transform を import します。
28 – 38 行目
def get_normalize_method(mean, std, no_mean_norm, no_std_norm):
if no_mean_norm:
if no_std_norm:
return Normalize([0, 0, 0], [1, 1, 1])
else:
return Normalize([0, 0, 0], std)
else:
if no_std_norm:
return Normalize(mean, [1, 1, 1])
else:
return Normalize(mean, std)こちらも spatial_transform に追加する内容となります。
40 – 55 行目
def inference(data_loader, model, result_path, class_names, no_average,
output_topk, opt):
print('inference')
spatial_transform = []
normalize = get_normalize_method(opt.mean, opt.std, opt.no_mean_norm,
opt.no_std_norm)
spatial_transform = [Resize(opt.sample_size)]
if opt.inference_crop == 'center':
spatial_transform.append(CenterCrop(opt.sample_size))
spatial_transform.append(ToTensor())
if opt.input_type == 'flow':
spatial_transform.append(PickFirstChannels(n=2))
spatial_transform.extend([ScaleValue(opt.value_scale), normalize])
spatial_transform = Compose(spatial_transform)spatial_transform を構成する部分となります。
67 – 97 行目
with torch.no_grad():
for i, (inputs, targets) in enumerate(data_loader):
data_time.update(time.time() - end_time)
from PIL import Image
video = []
clips = []
for i in range(1,17):
img = Image.open("../UCF101_images/UCF101/ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c01/image_{:05}.jpg".format(i))
video.append(img.convert('RGB'))
spatial_transform.randomize_parameters()
clip = [spatial_transform(img) for img in video]
clips.append(torch.stack(clip, 0).permute(1, 0, 2, 3))
print(len(clips), len(clips[0]), clips[0][0].shape, inputs[0][0].shape)
for i, j, k, l, m, n in zip(inputs[0][0], inputs[0][1], inputs[0][2], clips[0][0], clips[0][1], clips[0][2]):
ii = i.cpu().detach().numpy()
jj = j.cpu().detach().numpy()
kk = k.cpu().detach().numpy()
ll = l.cpu().detach().numpy()
mm = m.cpu().detach().numpy()
nn = n.cpu().detach().numpy()
cv2.imshow("input1", ii)
cv2.imshow("input2", jj)
cv2.imshow("input3", kk)
cv2.imshow("clip1", ll)
cv2.imshow("clip2", mm)
cv2.imshow("clip3", nn)
cv2.waitKey(0)
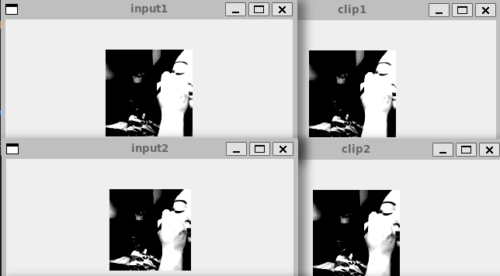
aこちらが、実際に 16 フレーム分画像を読み込んで spatial_transform で前処理を 16 フレームに実施し、opencv で画像を表示している部分です。a で止めています。
画像を比較してみます。

どちらも同じ画像が表示されていますね。
無事に前処理ができているので、あとは Tensor 型に変換したり、他の 16 枚の画像と連結したりするだけとなります。
実際に入力データを作成してモデルに投げ、結果を確認するのは次回にします。
おわりに
今回は入力データを揃える方法を説明しました。
次回は、プログラムを整えつつ、結果の確認も実施できたらと思います。


コメント