はじめに
前回は、単一の推論ファイルを作成しました。

今回は、カスタムデータで学習させる方法について説明します。
前提条件
前提条件は以下の通りです。
- Python3.9
- torch == 1.13.0+cu117, torchvision == 0.14.0+cu117
- 作業は WSL2 で実施します
学習データの準備
学習データを準備していきます。
各種データは hmdb-51 データセットから一部を使用しています。
train.avi
test.avi
defect.avi
3つの動画を用意しました。
test.avi は推論時に使用します。
動画を画像に変換
まずは動画を 1 フレーム毎に画像に変換していきます。
mkdir custom_data
cd custom_data
mkdir images
mkdir movies
cd movies今作成した movies フォルダに train.avi, test.avi, defect.avi を保存してください。
移動したら、変換プログラムを作成していきます。
cd ../../3D-ResNets-PyTorch
touch convert_movie2img.pyconvert_movie2img.py
import cv2
import glob
import os
folderpath = glob.glob("../custom_data/movies/*.avi")
for f in folderpath:
basename = os.path.basename(f)
folder_name = os.path.splitext(basename)[0]
os.mkdir("../custom_data/images/"+folder_name)
cap = cv2.VideoCapture(f)
index = 1
# 不要な部分は飛ばす
for i in range(10):
ret = cap.grab()
while True:
# 1フレーム毎を学習対象とする
for i in range(1):
ret = cap.grab()
ret, frame = cap.retrieve()
if not ret:
break
img_name = "../custom_data/images/"+folder_name+"/image_{:05}.jpg".format(index)
img = cv2.resize(frame, (320,240))
cv2.imwrite(img_name, img)
index += 1
print(basename)
実行します。
python3 convert_movie2img.pycustom_data/images フォルダに train, test, defect フォルダが作成されます。
それを以下のように変更してください。
images
├── Defect
│ ├── DefectTest
│ └── WalkDefect
└── Walk
├── Walk
└── WalkTestWalkDefect, DefectTest は defect.avi の画像を
Walk は train.avi の画像を
WalkTest は test.avi の画像を保存してください。
学習用プログラムの修正
datasets/videodataset.py の 80,81 行目
if i % (n_videos // 5) == 0:
print('dataset loading [{}/{}]'.format(i, len(video_ids)))
↓
# if i % (n_videos // 5) == 0:
# print('dataset loading [{}/{}]'.format(i, len(video_ids)))main.py の 245-253 行目
val_loader = torch.utils.data.DataLoader(val_data,
batch_size=(opt.batch_size //
opt.n_val_samples),
shuffle=False,
num_workers=opt.n_threads,
pin_memory=True,
sampler=val_sampler,
worker_init_fn=worker_init_fn,
collate_fn=collate_fn)
↓
val_loader = torch.utils.data.DataLoader(val_data,
batch_size=(opt.batch_size),
shuffle=False,
num_workers=opt.n_threads,
pin_memory=True,
sampler=val_sampler,
worker_init_fn=worker_init_fn,
collate_fn=collate_fn)これで修正は完了です。
アノテーションデータの作成
アノテーションデータの作成をしていきます。
アノテーションデータとは言えど、クラス名・ファイルパス・動画フレーム数 を設定するくらいです。
touch custom_data.jsoncustom_data.json
{"labels": ["Walk", "Defect"],
"database": {
"Walk":
{"subset": "training", "annotations": {"label": "Walk", "segment": [1, 85]}},
"WalkDefect":
{"subset": "validation", "annotations": {"label": "Defect", "segment": [1, 61]}},
"WalkTest":
{"subset": "validation", "annotations": {"label": "Walk", "segment": [1, 222]}},
"DefectTest":
{"subset": "training", "annotations": {"label": "Defect", "segment": [1, 61]}}
}
}上から説明していきます。
"labels": ["Walk", "Defect"]これはクラス名です。labels は固定で Walk, Defect はクラス名です。
"database": {database タグ以降に動画一つ一つのアノテーションデータを作成していきます。
"Walk":
{"subset": "training", "annotations": {"label": "Walk", "segment": [1, 85]}},Walk タグは、動画が保存されているフォルダを指定します。
subset は training, validation の二つから選択します。
annotations タグがクラス名と動画フレームを指定します。
label はクラス名を指定します。
segment は [1, 画像の枚数+1] を指定します。
ここまできたら、あとは学習を実行するだけです。
学習の実行
学習は、以下のコマンドで実行します。
mkdir custom_results
python3 main.py --root_path ./ --video_path ../custom_data/images --annotation_path ./custom_data.json --result_path custom_results --dataset ucf101 --model resnet --model_depth 50 --n_classes 2 --batch_size 2 --n_threads 1 --n_epochs 400 --checkpoint 20 --learning_rate 0.01n_epochs, checkpoint, learning_rate は適当に設定してください。
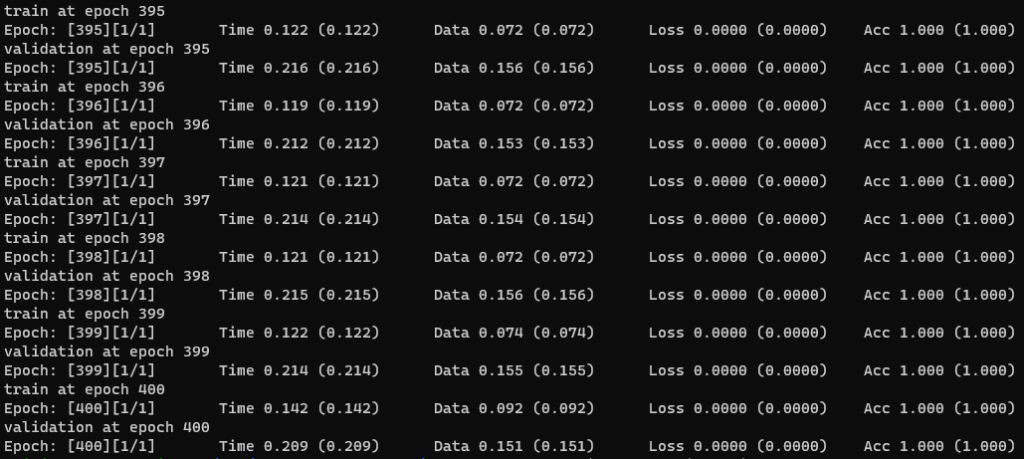
こんな感じで、学習が完了します。
学習結果の確認
学習結果を確認するプログラムを作成します。
single_inference.py
from pathlib import Path
import random
from PIL import Image
import numpy as np
import torch
import torch.nn.functional as F
from torch.backends import cudnn
import matplotlib.pyplot as plt
from opts import parse_opts
from model import generate_model
from mean import get_mean_std
from spatial_transforms import (Compose, Normalize, Resize, CenterCrop,ToTensor, ScaleValue, PickFirstChannels)
def json_serial(obj):
if isinstance(obj, Path):
return str(obj)
def get_opt():
opt = parse_opts()
opt.mean, opt.std = get_mean_std(opt.value_scale, dataset=opt.mean_dataset)
opt.n_input_channels = 3
opt.resume_path = "./custom_results/save_400.pth"
opt.root_path = "./"
opt.device = torch.device('cpu' if opt.no_cuda else 'cuda')
if not opt.no_cuda:
cudnn.benchmark = True
opt.output_topk = 1
opt.n_classes = 2
opt.model_depth = 50
opt.arch = '{}-{}'.format(opt.model, opt.model_depth)
return opt
def resume_model(resume_path, arch, model):
print('loading checkpoint {} model'.format(resume_path))
checkpoint = torch.load(resume_path, map_location='cpu')
assert arch == checkpoint['arch']
if hasattr(model, 'module'):
model.module.load_state_dict(checkpoint['state_dict'])
else:
model.load_state_dict(checkpoint['state_dict'])
return model
def get_normalize_method(mean, std, no_mean_norm, no_std_norm):
if no_mean_norm:
if no_std_norm:
return Normalize([0, 0, 0], [1, 1, 1])
else:
return Normalize([0, 0, 0], std)
else:
if no_std_norm:
return Normalize(mean, [1, 1, 1])
else:
return Normalize(mean, std)
def get_inference_utils(opt):
assert opt.inference_crop in ['center', 'nocrop']
normalize = get_normalize_method(opt.mean, opt.std, opt.no_mean_norm,
opt.no_std_norm)
spatial_transform = [Resize(opt.sample_size)]
if opt.inference_crop == 'center':
spatial_transform.append(CenterCrop(opt.sample_size))
spatial_transform.append(ToTensor())
if opt.input_type == 'flow':
spatial_transform.append(PickFirstChannels(n=2))
spatial_transform.extend([ScaleValue(opt.value_scale), normalize])
spatial_transform = Compose(spatial_transform)
return spatial_transform
def inference_main(opt):
random.seed(opt.manual_seed)
np.random.seed(opt.manual_seed)
torch.manual_seed(opt.manual_seed)
model = generate_model(opt)
model = resume_model(opt.resume_path, opt.arch, model)
model.eval()
spatial_transform = get_inference_utils(opt)
with torch.no_grad():
video = []
for i in range(1,17):
# img = Image.open("../UCF101_images/UCF101/ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c01/image_{:05}.jpg".format(i))
img = Image.open("../custom_data/images/Walk/WalkTest/image_{:05}.jpg".format(i))
# img = Image.open("../custom_data/images/Defect/DefectTest/image_{:05}.jpg".format(i))
video.append(img.convert('RGB'))
fig = plt.figure()
for i, im in enumerate(video):
fig.add_subplot(4,4,i+1).set_title(str(i))
plt.imshow(im)
plt.show()
# single data
spatial_transform.randomize_parameters()
clip = [spatial_transform(img) for img in video]
clips = torch.unsqueeze((torch.stack(clip, 0).permute(1, 0, 2, 3)),0)
outputs = model(clips)
print(outputs)
outputs = F.softmax(outputs, dim=1).cpu()
print(outputs)
sorted_scores, locs = torch.topk(torch.mean(outputs, dim=0),
k=min(opt.output_topk, opt.n_classes))
print("score:",sorted_scores.item(), "class:",locs.item())
if __name__ == '__main__':
opt = get_opt()
inference_main(opt)上記を実行すると、まずは入力データが表示されます。
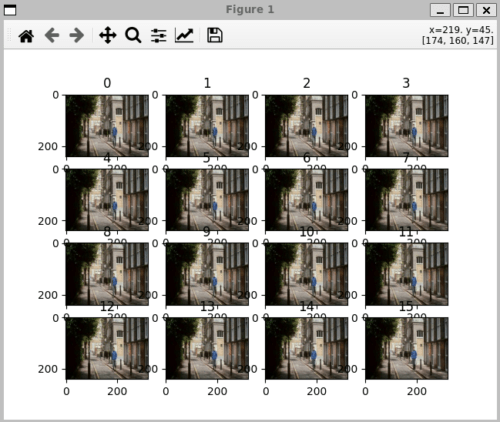
コンソールに結果が表示されます。
loading checkpoint ./custom_results/save_400.pth model
tensor([[ 211.3719, -216.9188]])
tensor([[1., 0.]])
score: 1.0 class: 0続いて、Defect クラスが検出できているか確認します。
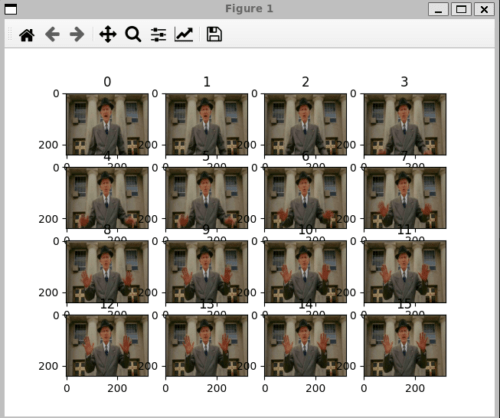
出力は以下のようになります。
loading checkpoint ./custom_results/save_400.pth model
tensor([[-23.0008, 22.9723]])
tensor([[1.0818e-20, 1.0000e+00]])
score: 1.0 class: 1問題なく検出できていますね!
おわりに
今回は、3D-ResNets-PyTorch をカスタムデータで学習させる方法について説明しました。
これで動画認識できるようになりました。
次に気になる AI がありましたら、また説明できればと思います。

コメント