はじめに
前回は 3D-ResNets-PyTorch のモデルへ渡す入力データの作成と結果の確認を行いました。

今回は、単一のプログラムファイルにまとめて、コードを整理していきます。
前提条件
前提条件は以下の通りです。
- Python3.9
- torch == 1.13.0+cu117, torchvision == 0.14.0+cu117
- 作業は WSL2 で実施します
推論プログラム
single_inference.py を以下のように作成してください。
from pathlib import Path
import random
from PIL import Image
import numpy as np
import torch
import torch.nn.functional as F
from torch.backends import cudnn
from opts import parse_opts
from model import generate_model
from mean import get_mean_std
from spatial_transforms import (Compose, Normalize, Resize, CenterCrop,ToTensor, ScaleValue, PickFirstChannels)
def json_serial(obj):
if isinstance(obj, Path):
return str(obj)
def get_opt():
opt = parse_opts()
opt.mean, opt.std = get_mean_std(opt.value_scale, dataset=opt.mean_dataset)
opt.n_input_channels = 3
opt.resume_path = "./results/save_200.pth"
opt.root_path = "./"
opt.device = torch.device('cpu' if opt.no_cuda else 'cuda')
if not opt.no_cuda:
cudnn.benchmark = True
opt.output_topk = 1
opt.n_classes = 10
opt.model_depth = 50
opt.arch = '{}-{}'.format(opt.model, opt.model_depth)
return opt
def resume_model(resume_path, arch, model):
print('loading checkpoint {} model'.format(resume_path))
checkpoint = torch.load(resume_path, map_location='cpu')
assert arch == checkpoint['arch']
if hasattr(model, 'module'):
model.module.load_state_dict(checkpoint['state_dict'])
else:
model.load_state_dict(checkpoint['state_dict'])
return model
def get_normalize_method(mean, std, no_mean_norm, no_std_norm):
if no_mean_norm:
if no_std_norm:
return Normalize([0, 0, 0], [1, 1, 1])
else:
return Normalize([0, 0, 0], std)
else:
if no_std_norm:
return Normalize(mean, [1, 1, 1])
else:
return Normalize(mean, std)
def get_inference_utils(opt):
assert opt.inference_crop in ['center', 'nocrop']
normalize = get_normalize_method(opt.mean, opt.std, opt.no_mean_norm,
opt.no_std_norm)
spatial_transform = [Resize(opt.sample_size)]
if opt.inference_crop == 'center':
spatial_transform.append(CenterCrop(opt.sample_size))
spatial_transform.append(ToTensor())
if opt.input_type == 'flow':
spatial_transform.append(PickFirstChannels(n=2))
spatial_transform.extend([ScaleValue(opt.value_scale), normalize])
spatial_transform = Compose(spatial_transform)
return spatial_transform
def inference_main(opt):
random.seed(opt.manual_seed)
np.random.seed(opt.manual_seed)
torch.manual_seed(opt.manual_seed)
model = generate_model(opt)
model = resume_model(opt.resume_path, opt.arch, model)
model.eval()
spatial_transform = get_inference_utils(opt)
with torch.no_grad():
video = []
for i in range(1,17):
img = Image.open("../UCF101_images/UCF101/ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c01/image_{:05}.jpg".format(i))
video.append(img.convert('RGB'))
# single data
spatial_transform.randomize_parameters()
clip = [spatial_transform(img) for img in video]
clips = torch.unsqueeze((torch.stack(clip, 0).permute(1, 0, 2, 3)),0)
outputs = model(clips)
outputs = F.softmax(outputs, dim=1).cpu()
sorted_scores, locs = torch.topk(torch.mean(outputs, dim=0),
k=min(opt.output_topk, opt.n_classes))
print("score:",sorted_scores.item(), "class:",locs.item())
if __name__ == '__main__':
opt = get_opt()
inference_main(opt)上記を実行すると、以下の出力が得られます。
loading checkpoint ./results/save_200.pth model
score: 0.8489916324615479 class: 1前回と同じ結果が得られています。
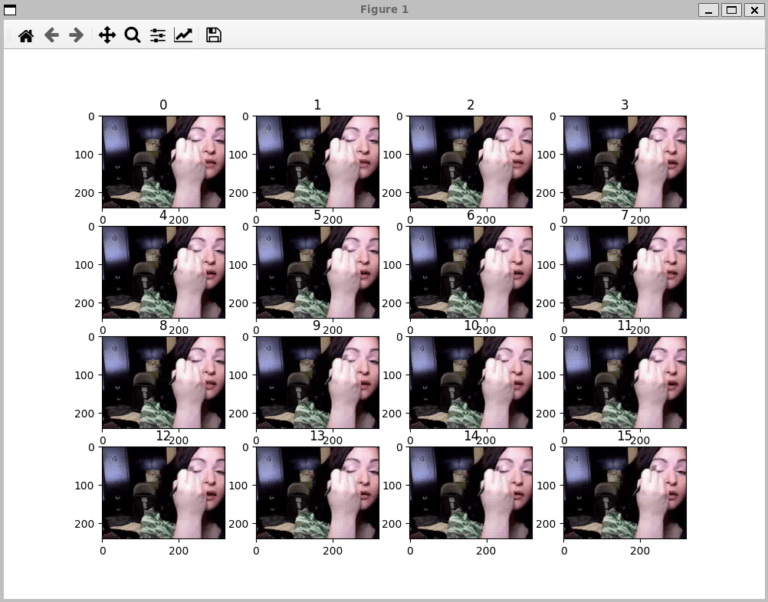
画像が見たい場合は
fig = plt.figure()
for i, im in enumerate(video):
fig.add_subplot(4,4,i+1).set_title(str(i))
plt.imshow(im)
plt.show()上記を追加してみてください。
フレームを飛ばしたりするとどうなるのか気になりますね。
その辺はカスタムデータで学習させた後にテストしてみます。
おわりに
今回は短いですが、ここまでとします。
次回からは、カスタムデータで学習する方法について説明していきます。


コメント