はじめに
前回までは SPADE を学習・推論させる方法について説明しました。

今回は同様の方法を PaDiM にも適用する方法について説明します。
前提条件
前提条件は以下の通りです。
- python3.9
- torch == 1.12.1+cu113
ind_knn_ad の github はこちらです。
学習
学習の準備
indad/models.py の PaDiM クラスの fit 関数の末尾に以下を追加してください。
x = self.E_inv.to('cpu').detach().numpy().copy()
np.save("./npy_data/E_inv.npy", x)
x = self.means_reduced.to('cpu').detach().numpy().copy()
np.save("./npy_data/means_reduced.npy", x)
x = self.r_indices.to('cpu').detach().numpy().copy()
np.save("./npy_data/r_indices.npy", x)各種変数を npy 形式で保存します。
学習用コード
train.py を以下のようにしてください。
from indad.models import SPADE, PaDiM, PatchCore
from indad.data import MVTecDataset
import cv2
import torch
import numpy as np
from torchvision import transforms
from torch import tensor
IMAGENET_MEAN = tensor([.485, .456, .406])
IMAGENET_STD = tensor([.229, .224, .225])
SIZE = 224
filename = "./weights/PaDiM.pth"
# model = SPADE(k=25, backbone_name="wide_resnet50_2")
model = PaDiM(d_reduced=350, backbone_name="wide_resnet50_2")
# model = PatchCore(f_coreset=.10, backbone_name="wide_resnet50_2")
# model.to("cuda")
train_ds, test_ds = MVTecDataset("custom", SIZE).get_dataloaders()
# feed healthy dataset
model.fit(train_ds)
# torch.save(model, filename)
torch.save(model.state_dict(), filename)
print("model saved to: ", filename)上記を実行すると、以下の出力が得られます。
100%|██████████| 1000/1000 [03:07<00:00, 5.34it/s]
PaDiM: (randomly) reducing 1792 dimensions to 350.
model saved to: ./weights/PaDiM.pth推論
推論の準備
indad/models.py の PaDiM クラスの predict 関数を以下のように変更してください。
def predict(self, sample):
feature_maps = self(sample)
resized_maps = [self.resize(fmap) for fmap in feature_maps]
fmap = torch.cat(resized_maps, 1)
# reduce
x_ = fmap[:,self.r_indices.long(),...] - self.means_reduced
left = torch.einsum('abkl,bckl->ackl', x_, self.E_inv)
s_map = torch.sqrt(torch.einsum('abkl,abkl->akl', left, x_))
scaled_s_map = torch.nn.functional.interpolate(
s_map.unsqueeze(0), size=(self.image_size,self.image_size), mode='bilinear'
)
return torch.max(s_map), scaled_s_map[0, ...]変更点は reduce の x_ のみです。 LongTensor型に変更しました。
続いて、standby関数を追加します。
def standby(self):
largest_fmap_size = torch.LongTensor([56, 56])
self.resize = torch.nn.AdaptiveAvgPool2d(largest_fmap_size)
self.E_inv = np.load("./npy_data/E_inv.npy")
self.E_inv = torch.from_numpy(self.E_inv.astype(np.float32)).clone()
self.means_reduced = np.load("./npy_data/means_reduced.npy")
self.means_reduced = torch.from_numpy(self.means_reduced.astype(np.float32)).clone()
self.r_indices = np.load("./npy_data/r_indices.npy")
self.r_indices = torch.from_numpy(self.r_indices.astype(np.int32)).clone()largest_fmap_size は今回のデータセットのみに適していますが、異なる場合は学習時に largest_fmap_sizeを出力して確認してみてください。
推論コード
inference.py を以下のようにしてください。
from indad.models import SPADE, PaDiM, PatchCore
import cv2
import torch
import numpy as np
from torchvision import transforms
from torch import tensor
IMAGENET_MEAN = tensor([.485, .456, .406])
IMAGENET_STD = tensor([.229, .224, .225])
SIZE = 224
filename = "./weights/PaDiM.pth"
load_model = PaDiM(d_reduced=350, backbone_name="wide_resnet50_2")
load_model.load_state_dict(torch.load(filename))
load_model.standby()
transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize(SIZE, interpolation=transforms.InterpolationMode.BICUBIC),
transforms.CenterCrop(SIZE),
transforms.ToTensor(),
transforms.Normalize(IMAGENET_MEAN, IMAGENET_STD)
])
# get predictions
good_frame = cv2.imread("./good.png")
good_frame = cv2.cvtColor(good_frame,cv2.COLOR_BGR2RGB)
good_x = transform(good_frame)
good_x = good_x.unsqueeze(0)
defect_frame = cv2.imread("./defect.png")
defect_frame = cv2.cvtColor(defect_frame,cv2.COLOR_BGR2RGB)
defect_x = transform(defect_frame)
defect_x = defect_x.unsqueeze(0)
load_model.eval()
with torch.no_grad():
img_lvl_anom_score, pxl_lvl_anom_score = load_model.predict(good_x)
print("good frame score is: ", img_lvl_anom_score)
img_lvl_anom_score, pxl_lvl_anom_score = load_model.predict(defect_x)
print("defect frame score is: ", img_lvl_anom_score)
print(pxl_lvl_anom_score.shape)
anom_frame = pxl_lvl_anom_score.numpy().reshape(224,224,1).astype("uint8")
print(anom_frame.shape)
cv2.imshow("frame", anom_frame)
cv2.waitKey(0)
cv2.destroyAllWindows()基本的な流れは SPADE と変わりありません。
出力画像は以下のようになります。
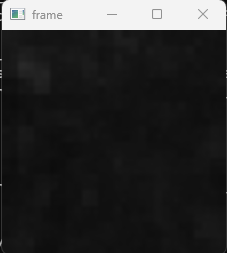
少し見にくいですが、不良部分のみうっすらと白いことが分かります。
おわりに
今回は PaDiM の実行方法について説明しました。
SPADE よりも白く反応する部分が少ないので、製造業での外観異常検査に向いていそうです。
次回は、PatchCore で同様の手法を実装していきます。



コメント