
はじめに
今回は低解像度の画像を高解像度に変換する超解像に用いられるAIに関して、そのデモスクリプトをテストしていきます。
低解像度の映像を高解像度に変換することによって、防犯カメラの映像のAI認識精度を高めたり、逆に誤検知を減らしたり、様々な活用方法が考えられます。
今回使用するのは Real-ESRGAN というAIで、github はこちらにあります。
前提条件
前提条件は、以下の通りです。
- Windows11 ( Windows11 のみでテストしています。
- Python3.9
- torch == 1.12.1+cu113
必要なライブラリのインストール
README に従って必要なものをインストールしていきます。
pip install basicsr
pip install facexlib
pip install gfpgan
git clone https://github.com/xinntao/Real-ESRGAN.git
cd Real-ESRGAN
python setup.py developこれで完了です。
事前学習モデルのダウンロード
ページ中部よりダウンロードしてください。
下記画像の赤丸部分からダウンロードできます。
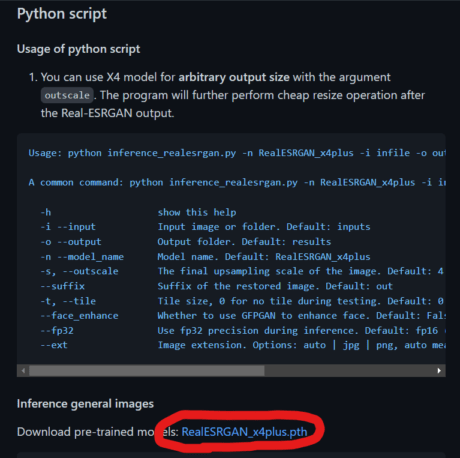
ダウンロードしたら Real-ESRGAN/weights へ保存してください。
超解像の実行
超解像は、以下のコマンドを使用します。
python inference_realesrgan.py -n RealESRGAN_x4plus -i inputsこれだけで、inputs フォルダ内の画像に対して超解像を実行します。
結果の確認
result フォルダに保存されている結果を確認してみましょう。
元画像

超解像結果

木の枝の細部まで表現されています。
さらに、再現された木の枝を見ると、枝分かれまで表現されています。
デモ画像は他にもあるので、動かした後は確認してみてください。
その他のオプション
ベースとなる実行方法は以下の通りです。
python inference_realesrgan.py -n RealESRGAN_x4plus -i inputs-i オプション
-i は直接画像を指定するか、画像が保存されているフォルダ名を指定します。
-n オプション
-n は使用するモデルを指定します。
- RealESRGAN_x4plus
- RealESRNet_x4plus
- RealESRGAN_x4plus_anime_6B
- RealESRGAN_x2plus
- realesr-animevideov3
- realesr-general-x4v3
上記6種が使用できます。
-o オプション
-o フォルダ名 で出力先を指定します。デフォルトは results です。
-s オプション
拡大する倍率を指定します。デフォルトは 4 です。
–suffix オプション
出力するファイル名にサフィックスを付加します。
–fp32 オプション
デフォルトでは float16 で推論しますが、–fp32 を指定すると float32 で推論します。
–ext オプション
–ext jpg で jpg フォーマットで指定します。png も指定できます。
–face_enhance
–face_enhance で 顔の超解像を実行する GFPGAN を使用することができます。
これには、先ほどインストールした facexlib が必要となります。
また、グレースケールには対応していません。
グレースケールも適用させたい場合は
facexlib/utils/inference_realesrgan.py の 350 行目あたりを変更する必要があります。
if len(upsample_img.shape) == 3 and upsample_img.shape[2] == 4: # alpha channel
alpha = upsample_img[:, :, 3:]
upsample_img = inv_soft_mask * pasted_face + (1 - inv_soft_mask) * upsample_img[:, :, 0:3]
upsample_img = np.concatenate((upsample_img, alpha), axis=2)
else:
upsample_img = inv_soft_mask * pasted_face + (1 - inv_soft_mask) * upsample_img
↓
if len(upsample_img.shape) != 3:
upsample_img = upsample_img.reshape(1404, 2000, 1)
if len(upsample_img.shape) == 3 and upsample_img.shape[2] == 4: # alpha channel
alpha = upsample_img[:, :, 3:]
upsample_img = inv_soft_mask * pasted_face + (1 - inv_soft_mask) * upsample_img[:, :, 0:3]
upsample_img = np.concatenate((upsample_img, alpha), axis=2)
else:
upsample_img = inv_soft_mask * pasted_face + (1 - inv_soft_mask) * upsample_img上記のように変更すれば対応可能です。
おわりに
今回は Real-ESRGAN のデモプログラムを動かしました。
pip install したライブラリとの相性が少し悪くエラーが出るかもしれませんが、4倍に解像度を上げてもかなりきれいな画像を出力できています。
この技術はインスタンスセグメンテーション等でも使用できそうです。
次回は、引数を使用せずに推論を動かせるようにしていきます。



コメント