はじめに
前回は、 yolov5 と open3d を組み合わせてマウスの点群を切り出す方法について説明しました。

今回は、そのコードについて説明していきます。
前提条件
前提条件は、以下の通りです。
- pyrealsense2
- OpenCV ==4.6.0
- Python == 3.9.13
- Windows11
- open3D == 0.16.0
- pytorch == 1.12.1
コード再掲
import pyrealsense2 as rs
import numpy as np
import cv2
import open3d as o3d
import datetime
import torch
from yolov5_object.models.common import DetectMultiBackend
from yolov5_object.utils.augmentations import letterbox
from yolov5_object.utils.general import non_max_suppression
# ======================= yolov5 ========================= #
frame = cv2.imread("./output.png")
h, w, _ = frame.shape
device = "cuda"
model = DetectMultiBackend("./yolov5/yolov5s.pt", device=device, dnn=False, data='./yolov5/data/coco128.yaml', fp16=True)
stride, names, pt = model.stride, model.names, model.pt
conf_thres = 0.45
iou_thres = 0.25
classes = None
# Padded resize
img = letterbox(frame, 640, stride=stride, auto=True)[0]
# Convert
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
im = torch.from_numpy(img).to(device)
im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim
pred = model(im, augment=False, visualize=False)
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, False, max_det=50)
pred_cpu = pred[0][0].cpu().detach().numpy()
index = int(pred_cpu[5])
# print(pred_cpu, index, names[index])
x1, y1, x2, y2 = int(pred_cpu[0]), int(pred_cpu[1]), int(pred_cpu[2]), int(pred_cpu[3])
yolo_clip_image = frame[y1:y2, x1:x2]
# ======================= yolov5 to open3d ========================= #
# image shape is h, w, ch
# yolov5 coordinate origin is left-top
# realsense coordinate origin is camera center = w/2, h/2
open3d_center_w, open3d_center_h, margin = w/2, h/2, 5
# shift center coordinate
yolo_obj_x1, yolo_obj_y1 = (x1-open3d_center_w-margin)/1000, (y1-open3d_center_h-margin)/1000
yolo_obj_x2, yolo_obj_y2 = (x2-open3d_center_w+margin)/1000, (y2-open3d_center_h+margin)/1000
bb = o3d.geometry.AxisAlignedBoundingBox(
np.array([[yolo_obj_x1],[yolo_obj_y1],[-1.0]]),
np.array([[yolo_obj_x2],[yolo_obj_y2],[1.0]]),
)
# ======================= open3d ========================= #
pcd = o3d.io.read_point_cloud("./output.ply")
pcd.transform([[1, 0, 0, 0], [0, -1, 0, 0], [0, 0, -1, 0], [0, 0, 0, 1]])
crop_pcd = pcd.crop(bb)
# Flip the pointclouds, otherwise they will be upside down.
o3d.visualization.draw([crop_pcd])
コード説明
from yolov5_object.models.common import DetectMultiBackend
from yolov5_object.utils.augmentations import letterbox
from yolov5_object.utils.general import non_max_suppressionyolov5_object.models や、yolov5_object.utils は、前回の記事で作成した yolov5_object フォルダ内の models フォルダ、utils フォルダを指しています。
models フォルダ内の DetectMultiBackend は、common.py の関数ですが、common.py の import 分も yolov5_object. … と変更していく必要があります。
エラー文にどこの .py ファイルでエラーが出ているか表示されますので何回も動かして依存関係を解消していってください。
yolov5 での物体検出
frame = cv2.imread("./output.png")
h, w, _ = frame.shape
device = "cuda"
model = DetectMultiBackend("./yolov5/yolov5s.pt", device=device, dnn=False, data='./yolov5/data/coco128.yaml', fp16=True)画像を読み込み、device は cuda を指定します。もちろん、cpu でも実行可能です。
DetectMultiBackend へは yolov5s.pt, coco128.yaml を明示的に指定します。
dnn は使用しないので False、速度を上げるために半精度浮動小数 (fp16) を使用します。
stride, names, pt = model.stride, model.names, model.pt
conf_thres = 0.45
iou_thres = 0.25
classes = Nonestride, names, pt は、model から取得することが可能です。
conf_thres, iou_thres, classes はひとまずデフォルトの値にしておきます。
# Padded resize
img = letterbox(frame, 640, stride=stride, auto=True)[0]letterbox で入力画像を推論用にサイズ変更、パディングしておきます。
# Convert
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
im = torch.from_numpy(img).to(device)
im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dimletterbox を通した画像に対して、推論用に 配列の形状を変更します。
pred = model(im, augment=False, visualize=False)model() を呼び出して、推論します。
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, False, max_det=50)non_max_suppression で、検出位置がかぶっている矩形を削除します。
pred_cpu = pred[0][0].cpu().detach().numpy()
index = int(pred_cpu[5])
# print(pred_cpu, index, names[index])
x1, y1, x2, y2 = int(pred_cpu[0]), int(pred_cpu[1]), int(pred_cpu[2]), int(pred_cpu[3])出力結果を cpu に配置します。
index は、検出のラベルを表していますが、今回はマウスしか映っていないので使用しません。
RGB画像上での 切り抜く矩形を (x1, y1), (x2, y2) とします。
yolo_clip_image = frame[y1:y2, x1:x2]RGB画像も切り抜いておきます。
open3d での切り出し
# image shape is h, w, ch
# yolov5 coordinate origin is left-top
# realsense coordinate origin is camera center = w/2, h/2
open3d_center_w, open3d_center_h, margin = w/2, h/2, 5
# shift center coordinate
yolo_obj_x1, yolo_obj_y1 = (x1-open3d_center_w-margin)/1000, (y1-open3d_center_h-margin)/1000
yolo_obj_x2, yolo_obj_y2 = (x2-open3d_center_w+margin)/1000, (y2-open3d_center_h+margin)/1000realsense で取得した pointcloud は、カメラの中心座標が (0, 0) となっているので、yolo の検出結果をシフトさせる必要があります。
また、座標の数値は m で取扱われるので、mm → m の変換を行います。
bb = o3d.geometry.AxisAlignedBoundingBox(
np.array([[yolo_obj_x1],[yolo_obj_y1],[-1.0]]),
np.array([[yolo_obj_x2],[yolo_obj_y2],[1.0]]),
)o3d.geometry.AxisAlignBoundingBox() は、numpy 配列で指定した空間を切り出します。
z方向は適当に -1.0 から 1.0 の間を切り抜くようにしていますので、ご自身の環境に合わせて変更してください。
pcd = o3d.io.read_point_cloud("./output.ply")
pcd.transform([[1, 0, 0, 0], [0, -1, 0, 0], [0, 0, -1, 0], [0, 0, 0, 1]])
crop_pcd = pcd.crop(bb)
# Flip the pointclouds, otherwise they will be upside down.
o3d.visualization.draw([crop_pcd])bb を定義したら、 output.ply を読み込んで transform を実行してから pcs.crop(bb) を実行してください。
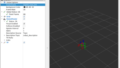
これで、以下のように点群が切り出しされると思います。

おわりに
今回は、yolov5 + open3d で点群を切り出すソースコードの内容を説明しました。
yolov5 は本当に便利ですね。様々なものと組み合わせることが可能です。
これで点群解析は一区切りとします。望んだ性能が出ませんでしたので。
C++ で作成しないと真価を発揮することはできなさそうです。

コメント