
はじめに
前回までは、画像内の領域・物体検出について説明しました。
今回は、画像自体が何を表すかを特定する方法について説明します。
色々な手法がありますが、学習・検出ともに高速な手法を取り上げます。
前提条件
前提条件は、以下の通りです。
- vit-pytorch == 0.40.2 (あとで説明します)
- pytorch == 1.11.0+cu113
- numpy == 1.23.3
- timm == 0.6.7
vit-pytorch の導入方法
VIT-Pytorch の導入方法は以下の通りです。
pip3 install vit-pytorch linformerViT-Pytorch の github に example があるので、github をダウンロードします。
mkdir ~/vit-dev
git clone https://github.com/lucidrains/vit-pytorch.git
cd vit-pytorchデータセットの準備
example 用のデータセットはこちらのページの Download All からダウンロードできます。
kaggle のアカウントが必要です。
ダウンロードフォルダにある test.zip と train.zip を、
~/vit-dev/vit-pytorch/examples に 移動してください。
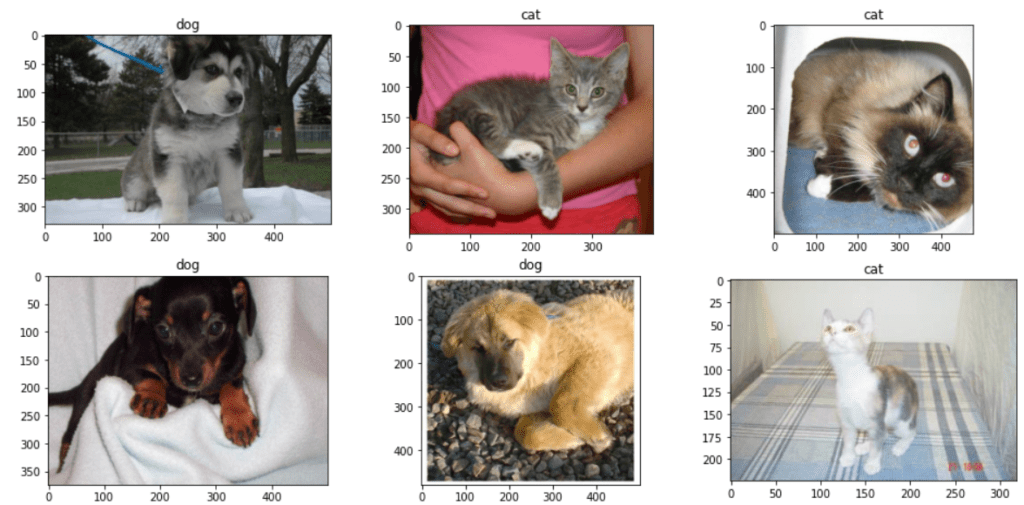
データセットの中身はこのような画像です。
vit-pytorch の examples を動かしてみる
example フォルダの中の、cats_and_dogs.ipynb を jupyter notebook で開いてみてください。
コードはそのままのものを使用しますので、重要な部分のみ抜粋します。
train_transforms = transforms.Compose(
[
transforms.Resize((224, 224)),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
]
)- transforms.Resize((224, 224)) … 画像を 224 x 224 にリサイズします。
- transforms.RandomResizedCrop(224) … ランダムに切り抜いて224にリサイズします。
- transforms.RandomHorizontalFlip() … 水平方向に反転します。
- transforms.ToTensor() … 画像をテンソル形式に変換します。
# Load Datasets
class CatsDogsDataset(Dataset):
def __init__(self, file_list, transform=None):
self.file_list = file_list
self.transform = transform
def __len__(self):
self.filelength = len(self.file_list)
return self.filelength
def __getitem__(self, idx):
img_path = self.file_list[idx]
img = Image.open(img_path)
img_transformed = self.transform(img)
label = img_path.split("/")[-1].split(".")[0]
label = 1 if label == "dog" else 0
return img_transformed, labelcats_and_dogs の画像データとファイル名から、Pytorch 用のデータセットを作成します。
__len__ と __getitem__ は、Pytorch のデータローダーに必要な関数ですので、忘れずに記載してください。
cat の場合は label = 1、dog の場合は、label = 0 とします。
複数クラスの場合は 0, 1, 2 … と増加させます。
train_data = CatsDogsDataset(train_list, transform=train_transforms)
train_loader = DataLoader(dataset = train_data, batch_size=batch_size, shuffle=True )先ほどのクラスで作成した train_data から、Pytorch の DataLoader 関数を使用して train_loader を作成します。
model = ViT(
dim=128,
image_size=224,
patch_size=32,
num_classes=2,
transformer=efficient_transformer,
channels=3,
).to(device)num_classes はクラス数を指定します。
image_size は推論に使用する画像サイズを使用します。
最後まで実行すると、以下のような出力が得られます。
100%
313/313 [01:27<00:00, 4.41it/s]
Epoch : 20 - loss : 0.5921 - acc: 0.6778 - val_loss : 0.5498 - val_acc: 0.7195acc: 0.6778, val_acc: 0.7195 なので、正解率は思ったほど高くありません。
さらなる精度向上にはファインチューニングが必要となるので、その方法を説明します。
vit-pytorch の精度向上
精度向上に関してはこちらのサイト様を参考にさせていただきました。
他にも様々な AI について解説していますので、是非ご参考ください。
Transformer はファインチューニングでその真価を発揮します。
cats_and_dogs.ipynb に新しい行を追加し、以下を追記してください。
CUDA のメモリエラーが出る場合は、タブの Kernel > Restart で再起動してください。
その後、データローダーを作成したら、以下を実行してください。
import timm
model = timm.create_model('vit_small_patch16_224', pretrained=True, num_classes=2)
model.to("cuda:0")
# loss function
criterion = nn.CrossEntropyLoss()
# optimizer
optimizer = optim.Adam(model.parameters(), lr=lr)
# scheduler
scheduler = StepLR(optimizer, step_size=1, gamma=gamma)
for epoch in range(epochs):
epoch_loss = 0
epoch_accuracy = 0
for data, label in tqdm(train_loader):
data = data.to(device)
label = label.to(device)
output = model(data)
loss = criterion(output, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
acc = (output.argmax(dim=1) == label).float().mean()
epoch_accuracy += acc / len(train_loader)
epoch_loss += loss / len(train_loader)
with torch.no_grad():
epoch_val_accuracy = 0
epoch_val_loss = 0
for data, label in valid_loader:
data = data.to(device)
label = label.to(device)
val_output = model(data)
val_loss = criterion(val_output, label)
acc = (val_output.argmax(dim=1) == label).float().mean()
epoch_val_accuracy += acc / len(valid_loader)
epoch_val_loss += val_loss / len(valid_loader)
print(
f"Epoch : {epoch+1} - loss : {epoch_loss:.4f} - acc: {epoch_accuracy:.4f} - val_loss : {epoch_val_loss:.4f} - val_acc: {epoch_val_accuracy:.4f}\n"
)
torch.save(model.state_dict(), "cats_and_dogs.pth")model = timm.create_model(‘vit_small_patch16_224’, pretrained=True, num_classes=2)
で、事前学習済みのモデルをダウンロードします。
こちらを実行すると以下のような出力が得られます。
Epoch : 1 - loss : 0.0784 - acc: 0.9677 - val_loss : 0.0245 - val_acc: 0.9912
Epoch : 20 - loss : 0.0391 - acc: 0.9848 - val_loss : 0.0320 - val_acc: 0.98901 エポック目から高精度となっています。20 エポック実行すると高精度な結果となりました。
おわりに
今回は、Vision Transformer の example を動かしました。
学習時間はかなり短いのに、高精度な結果を確認できたと思います。
次回は、Vision Transformer をカスタムデータにて学習する方法について説明します。

参考にさせていただいたサイト様
ViT 軒維持を書くにあたって参考にさせていただきました。
解説も丁寧で、他のAIの記事もとても勉強になります。



コメント